
Last Update:
Flexible particle system - How to start with Software Optimization

Table of Contents
It’s time to start improving the particle code and push more pixels to the screen! So far, the system is capable to animate and do some basic rendering with OpenGL. I’ve shown you even some nice pictures and movies… but how many particles can it hold? What is the performance? Is it that bad? What are the hot spots and bottlenecks? We need to figure that out in the first place!
Read more to get some theory behind the optimization process and how to apply this to our particle system example.
The Series
- Initial Particle Demo
- Introduction
- Particle Container 1 - problems
- Particle Container 2 - implementation
- Generators & Emitters
- Updaters
- Renderer
- Introduction to Software Optimization (this post)
- Tools Optimizations
- Code Optimizations
- Renderer Optimizations
- Summary
Introduction
As a software/game developer you, usually, want more and more… of everything actually! More pixels, more triangles, more FPS, more objects on the screen, bots, monsters. Unfortunately you don’t have endless resources and you end up with some compromises. The optimization process can help in reduction of performance bottlenecks and it may free some available powers hidden in the code.
Optimization shouldn’t be based on random guesses: “oh, I think, if I rewrite this code to SIMD, the game will run a bit faster”. How do you know that “this code” makes some real performance problems? Is investing there a good option? Will it pay off? It would be nice to have some clear guide, a direction.
In order to get some better understanding what to improved, you need to detect a base line of the system/game. In other words, you need to measure current state of the system and find hot spots and bottlenecks. Then think about factors you would like to improve…. and then… start optimizing the code! Such process might not be perfect, but at least you will minimize potential errors and maximize the outcome.
Of course, the process will not be finished with only one iteration. Every time you make a change, the process starts from the beginning. Do one small step at a time. Iteratively.
At the end your game/app should still work (without new bugs, hopefully) and it should run X times faster. The factor X, can be even measured accurately, if you do the optimization right.
The Software Optimization Process
According to this and this book, the process should look like this:
- Benchmark
- Find hot spots and bottlenecks
- Improve
- Test
- Go back

The whole process should not start after the whole implementation (when usually there is no time to do it), but should be executed during the project’s time. In case of our particle system I tried to think about possible improvements up front.
1. The benchmark
Having a good benchmark is a crucial thing. If you do it wrong then the whole optimization process can be even a waste of time.
From The Software Optimization Cookbook book:
The benchmark is the program or process used to:
- Objectively evaluate the performance of an application
- Provide repeatable application behavior for use with performance analysis tools.
The core and required attributes:
- Repeatable - gives the same results every time you run it.
- Representative - uses large portion of the main application’s use cases. It would be pointless if you focus only on a small part of it. For a game such benchmark could include most common scene or scene with maximum triangles/objects (that way simpler scenes will also work faster).
- Easy to run - you don’t want to spent hour to set up and run the benchmark. A benchmark is definitely harder to make than a unit test, but it would be nice if it runs as fast as possible. Another point is that it should produce easy to read output: for instance FPS report, timing report, simple logs… but not hundreds of lines of messages from internal subsystems.
- Verifiable - make sure the benchmark produces valid and meaningful results.
2. Find hot spots and bottlenecks

When you run your benchmark you will get some output. You can also run profiling tools and get more detailed results of how the application is performing.
But, having data is one, but actually, it is more important to understand it, analyze and have good conclusion. You need to find a problem that blocks the application from running at full speed.
Just to summarize:
- bottleneck - place in the system that makes whole application slower. Like the weakest element of a chain. For instance, you can have a powerful GPU, but without fast memory bandwidth you will not be able to feed this GPU monster with the data - it will wait.
- hot spot - place in the system that does crucial, intensive job. If you optimize such module then the whole system should work faster. For instance, if CPU is too hot then maybe offload some work to GPU (if it has some free compute resources available).
This part maybe the hardest. In a simple system it is easy to see a problem, but in a large scale software it can be quite tough. Sometimes it can be only one small function, or the whole design, or some algorithm used.
Usually it is better to use top down approach. For example:
Your framerate is too low. Measure your CPU/GPU utilization. Then go to CPU or GPU side. If CPU: think about your main subsystems: is this a animation module, AI, physics? Or maybe your driver cannot process so many draw calls? If GPU: vertex or fragment bound… Go down to the details.
3. Improve

Now the fun part! Improve something and the application should work better :)
What you can improve:
- at system level - look at utilization of your whole app. Are any resources idle? (CPU or GPU waiting?) Do you use all the cores?
- at algorithmic level - do you use proper data structures/algorithms? Maybe instead of O(n) solution you can reduce it to O(lg n) ?
- at micro level - the ‘funniest’ part, but do it only when the first two levels are satisfied. If you are sure, that nothing more can be designed better, you need to use some dirty code tricks to make things faster.
One note: Instead of rewriting everything to Assembler use you tools first. Today compilers are powerful optimizers as well. Another issue here is portability: one trick might not work on another platform.
4. Test
After you make a change test how the system behaves. Did you get 50% of the speed increase? Or maybe it is even slower?
Beside performance testing, please make sure you are not breaking anything! I know that making system 10% faster is nice, but your boss will not be happy if, thanks to this improvement, you introduce several hard-to-find bugs!

5. Go back
After you are sure everything works even better than before… just run your bechmark and repeat the process. It is better if you make a small, simple steps, rather than big, but complex. With smaller moves it is harder to make a mistake. Additionally, it is easy to revert the changes.
Profiling Tools
Main methods:
- custom timers/counters - you can create a separate configuration (based on Release mode) and enable set of counters or timers. For instance, you can place it in every function in a critical subsystem. You can generate call hierarchy and analyse it further on.
- instrumentation - tool adds special fragments of code to your executable so that it can measure the execution process.
- interception - tool intercepts API calls (for instance OpenGL - glIntercept, or DirectX) and later on analyses such register.
- sampling - tool stops the application at specific intervals and analyses the function stack. This method is usually much lighter than instrumentation.
Below a list of professional tools that can help:
- Intel® VTune™ Amplifier
- Visual Studio Profiler
- AMD CodeXL - FREE. AMD created a good, easy to use, profiling tool for CPU and GPU as well. Does the best job when you have also AMD CPU (that I don’t have ;/) but for Intel CPU’s it will give you at least timing reports.
- ValGrind - runs your app on a virtual machine and can detect various problems: from memory leaks to performance issues.
- GProf - Unix, uses a hybrid of sampling and instrumentation.
- Lots of others… here on wiki
Something more
Automate
I probably do not need to write this… but the more you automate the easiest your job will be.
This rule apply, nowadays, to almost everything: testing, setup of application, running the application, etc.
Have Fun!
The above process sounds very ‘professional’ and ‘boring’. There is also another factor that plays important role when optimizing the code: just have fun!
You want to make mistakes, you want to guess what to optimize and you want to learn new things. In the end, you will still get some new experience (even if you optimized a wrong method).
You might not have enough time for this at your day job, but what about some hobby project?
The more experience with the optimization process you have, the faster your code can run.

The particle system benchmark
So far, we’ve covered some theory and basic stuff. Now let’s apply this knowledge to our particle system case.
Particle System is only a small subsystem usually found in a game engine. In our system computation happens on the CPU side only so we do not have to measure GPU/CPU utilization in this case. For the sake of simplicity, we can now focus on the CPU part only.
Additionally, since the system is relatively small, we can focus on micro level optimizations primarily! In other words, we can think only about code hacks :) I, of course, assume, that my design of the system is the best. No need to change it :)
I’ve got two apps for tests: one - three particle effects
(“3effects”). And the second is CpuTest.
Those apps basically create a three different particle effects (see them in action here):
- Tunnel
- uses: position, color, velocity and time generators.
- color and euler updater only
- Attractors
- 3 emitters, each uses spherical velocity generator, color generator, position generator
- velocity color updater (color is based on velocity), attractor updater, euler updater and time updater.
- Fountain simulation
- position, color, velocity and time generators
- time, color, euler and floor updaters (bounce from floor level, simple ‘physics’)
I think, this set of effects can show most of system weaknesses. Focusing only on one effect might be misleading.
The apps share all the particle code, but the differ in rendering.
3effects uses OpenGL renderer and it is a nice interactive
visualization. This application might be used to measure also the GPU
performance (maybe in the future).
cpuTest focuses only on CPU part. It uses fake OpenGL renderer. That
way I could use all the effects code without changing any line of the
code!
CpuTest benchmark
Here is the main piece of code (simplified a bit):
for (size_t step = 0; step < PARTICLES_NUM_STEPS; ++step)
{
size_t numParticles{ START_NUM_PARTICLES + step*NUM_PARTICLES_STEP };
for (const auto &name : EFFECTS_NAME)
{
auto e = EffectFactory::create(name);
e->initialize(numParticles);
// start timer
for (size_t frame = 0; frame < FRAME_COUNT; ++frame)
{
e->cpuUpdate(DELTA_TIME);
}
// end timer
}
}
The above code:
- runs simulation from
START_NUM_PARTICLESup toSTART_NUM_PARTICLES + START_NUM_PARTICLES*NUM_PARTICLES_STEP - creates 3 different particle effects - using
EffectFactory - initializes an effect
- runs update method
FRAME_COUNTtimes (set by default to 200) - measures execution times and prints the results to the console (this code is hidden behind comments)
If we run this test we can get the following output:
count tunnel attractors fountain
1000 247 349 182
11000 2840 6249 2112
for instance, for 11000 particles, the attractors effects needs 6249 microseconds to do 200 frames of animation.
The results
PC Spec: Core i5 2400, Intel Sandy Bridge, 4Gb, VS 2013 Express
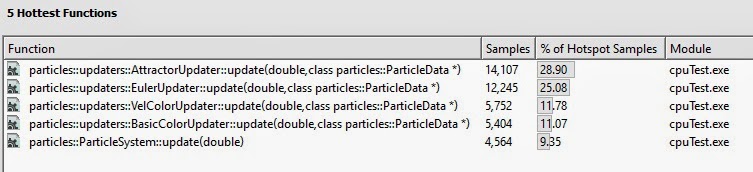
The attractor effect is quite heavy. One of the hot spots is located
in AttractorUpdater::update(double dt, ParticleData *p).
Also, EulerUpdater eats a lot of application time.
Additionally, from the 3effects application I have those numbers:
count tunnel attractors fountain
200k 59 fps 38 fps 59 fps
300k 30 fps 30 fps 59 fps
400k 29 fps 30 fps 32 fps
500k 19 fps 20 fps 29 fps
Fps count is also influenced by draw calls efficiency and gpu buffers update. For instance, it seems, there is some bottleneck when particle count is between 400k and 300k for fountain effect.
It seems that achieving 1 million of particle and 60 fps (or at least 45) will be a big challenge.
What to improve in the system
Micro
First guesses:
ParticleData::wake()- probablyif (m_countAlive < m_count)can be removed, additionally we do not have to callwakebecause we are just extending the size of alive particles. See container post and generators post for more info.ParticleData::kill()- the same situation withif.kill()marks a particle as dead and moves a particle from the end of the alive sequence to this dead position.ParticleData::swapData()- we move dead particles to the end of a sequence, since it is dead we do not need to update its params.
initial version:
count tunnel attractors fountain
291000 92712 183797 67415
after changes:
count tunnel attractors fountain
291000 89868 182029 66776
-3% -1% -1%
Not so bad for just a little logic tweaks. Maybe you can spot something else?
This are just random hits and, as you see, we did not get huuuge performance improvement. For more we need to dig deeper.
The compiler
Maybe there are some options available in the compiler (Visual Studio 2013 in my case) that can boost performance a bit? I will write about this in the next post.
SIMD and memory access patterns
Computation can be speed up using SIMD instruction. In the initial version, most of the time only scalar operations are used. There will be also a dedicated post about this topic.
Others
Probably, we could also go into concurrency and use some more threads to compute more particles. But, for now, I want to optimize on one thread only.
Another thing is related to the rendering. We need to look at GPU buffers update efficiency and memory transfer… as well as draw calls.
What’s Next
In this part we’ve made a few, but important, steps. We have the theory covered, the working benchmark and we identified some potential problems in the system. Having this information we can move forward and focus on the improvements. Next time I will write about compiler optimization - maybe, without changing code we can increase the speed.
Read next: Tools Optimizations
Your turn
- How do you perform the optimization process in your app or game?
- What tools do you use?
Please comment below or in this reddit thread
References
- The Software Optimization Cookbook: High Performance Recipes for IA-32 Platforms, 2nd Edition, Intel Press; 2nd edition (December 2005) - Contains lots of useful information, written in a light way. I’ve won it on GDC Europe 2011 :)
- [Video Game Optimization, by Eric Preisz](http://www.amazon.com/gp/product/1598634356/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1598634356&linkCode=as2&tag=bfilipek-20& linkId=XFFVH6Y36LB3PV3H) - another good book, also quite unique in this area. I would like to see the second edition - improved, updated and maybe extended.
- C++ For Game Programmers (Game Development Series)
- Agner`s optimization manuals
- Understanding Profiling Methods @MSDN
- Sampling vs Instrumentation/oktech-profiler docs
I've prepared a valuable bonus for you!
Learn all major features of recent C++ Standards on my Reference Cards!
Check it out here:
