
Last Update:
Persistent Mapped Buffers in OpenGL
Table of Contents
It seems that it’s not easy to efficiently move data from CPU to GPU. Especially, if we like to do it often - like every frame, for example. Fortunately, OpenGL (since version 4.4) gives us a new technique to fight this problem. It’s called persistent mapped buffers that comes from the ARB_buffer_storage extension.
Let us revisit this extension. Can it boost your rendering code?
Note:
This post is an introduction to the Persistent Mapped Buffers topic,
see
the Second Part with Benchmark
Results
Intro
First thing I’d like to mention is that there is already a decent number of articles describing Persistent Mapped Buffers. I’ve learned a lot especially from Persistent mapped buffers @ferransole.wordpress.com and Maximizing VBO upload performance! - javagaming.
This post serves as a summary and a recap for modern techniques used to handle buffer updates. I’ve used those techniques in my particle system
- please wait a bit for the upcoming post about renderer optimizations.
OK… but let’s talk about our main hero in this story: persistent mapped buffer technique.
It appeared in ARB_buffer_storage and it become core in OpenGL 4.4. It allows you to map buffer once and keep the pointer forever. No need to unmap it and release the pointer to the driver… all the magic happens underneath.
Persistent Mapping is also included in modern OpenGL set of techniques called “AZDO” - Aproaching Zero Driver Overhead. As you can imagine, by mapping buffer only once we significantly reduce number of heavy OpenGL function calls and what’s more important, fight synchronization problems.
One note: this approach can simplify the rendering code and make it more robust, still, try to stay as much as possible only on the GPU side. Any CPU to GPU data transfer will be much slower than GPU to GPU communication.
Moving data
Let’s now go through the process of updating the data in a buffer. We can do it in at least two different ways: glBuffer*Data and glMapBuffer*.
To be precise: we want to move some data from App memory (CPU) into GPU so that the data can be used in rendering. I’m especially interested in the case where we do it every frame, like in a particle system: you compute new position on CPU, but then you want to render it. CPU to GPU memory transfer is needed. Even more complicated example would be to update video frames: you load data from a media file, decode it and then modify texture data that is then displayed.
Often such process is referred as streaming.
In other terms: CPU is writing data, GPU is reading.
Although I mention ‘moving’, GPU can actually directly read from system memory (using GART). So there is no need to copy data from one buffer (on CPU side) to a buffer that is on the GPU side. In that approach we should rather think about ‘making data visible’ to GPU.
glBufferData/glBufferSubData
Those two procedures (available since OpenGL 1.5!) will copy your input data into pinned memory. Once it’s done an asynchronous DMA transfer can be started and the invoked procedure returns. After that call you can even delete your input memory chunk.
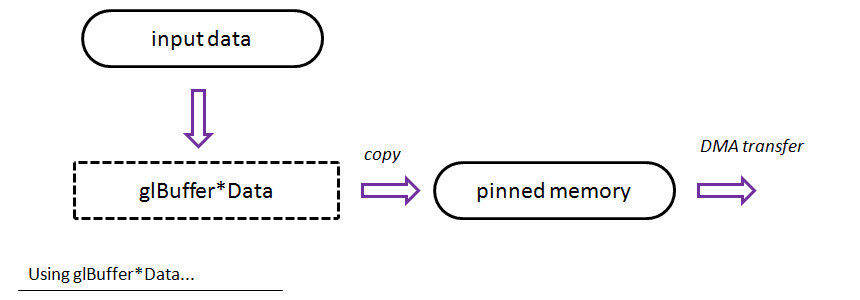
The above picture shows a “theoretical” flow for this method: data is passed to glBuffer*Data functions and then internally OpenGL performs DMA transfer to GPU…
Note: glBufferData invalidates and reallocates the whole buffer. Use glBufferSubData to only update the data inside.
glMap*/glUnmap*
With mapping approach you simply get a pointer to pinned memory (might depend on actual implementation!). You can copy your input data and then call glUnmap to tell the driver that you are finished with the update. So, it looks like the approach with glBufferSubData, but you manage copying data by yourself. Plus you get some more control about the entire process.
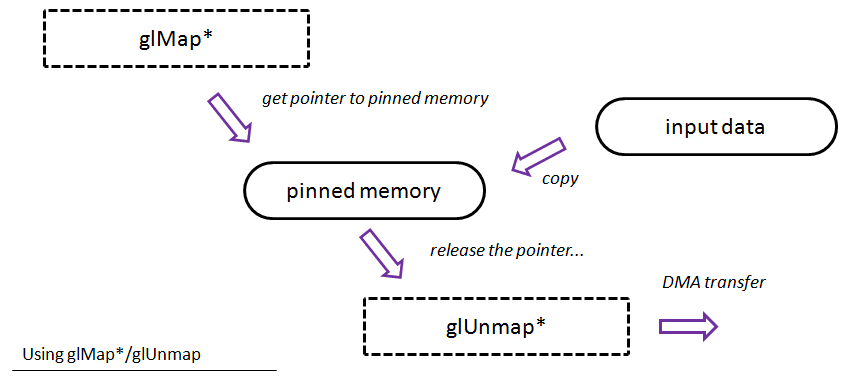
A “theoretical” flow for this method: you obtain a pointer to (probably) pinned memory, then you can copy your orignal data (or compute it), at the end you have to release the pointer via glUnmapBuffer method.
… All the above methods look quite easy: you just pay for the memory transfer. It could be that way if only there was no such thing as synchronization…
Synchronization
Unfortunately life is not that easy: you need to remember that GPU and CPU (and even the driver) runs asynchronously. When you submit a draw call it will not be executed immediately… it will be recorded in the command queue but will probably be executed much later by GPU. When we update a buffer data we might easily get a stall - GPU will wait while we modify the data. We need to be smarter about it.
For instance, when you call glMapBuffer the driver can create a mutex so that the buffer (which is a shared resource) is not modified by CPU and GPU at the same time. If it happens often, we’ll lose a lot of GPU power. GPU can block even in a situation when your buffer is only recorded to be rendered and not currently read.
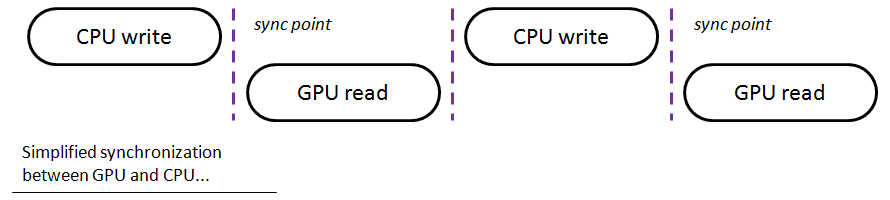
In the picture above I tried to show a very generic and simplified view of how GPU and CPU work when they need to synchronize - wait for each other. In a real life scenario those gaps might have different sizes and there might be multiple sync points in a frame. The less waiting the more performance we can get.
So, reducing synchronization problems is an another incentive to have everything happening on GPU.
Double (Multiple) buffering/Orphaning
Quite recommended idea is to use double or even triple buffering to solve the problem with synchronization:
- create two buffers
- update the first one
- in the next frame update the second one
- swap buffer ID…
That way GPU can draw (read) from one buffer while you will update the next one.
How can you do that in OpenGL?
- explicitly use several buffers and use round robin algorithm to update them.
- use glBufferData with NULL pointer before each update:
- the whole buffer will be recreated so we can store our data in completely new place
- the old buffer will be used by GPU - no synchronization will be needed
- GPU will probably figure out that the following buffer allocations are similar so it will use the same memory chunks. I remember that this approach was not suggested in older version of OpenGL.
- use glMapBufferRange with
GL_MAP_INVALIDATE_BUFFER_BIT- aditionally use UNSYNCHRONIZED bit and perform sync on your own.
- there is also a procedure called glInvalidateBufferData that does the same job
Triple buffering
GPU and CPU runs asynchronously… but there is also another factor: the driver. It may happen (and on desktop driver implementations it happens quite often) that the driver also runs asynchronously. To solve this, even more complicated synchronization scenario, you might consider triple buffering:
- one buffer for cpu
- one for the driver
- one for gpu
This way there should be no stalls in the pipeline, but you need to sacrifice a bit more memory for your data.
More reading on the @hacksoflife blog
- Double-Buffering VBOs
- Double-Buffering Part 2 - Why AGP Might Be Your Friend
- One More On VBOs - glBufferSubData
Persistent Mapping
Ok, we’ve covered common techniques for data streaming, but now, let’s talk about persistent mapped buffers technique in more details.
Assumptions:
GL_ARB_buffer_storagemust be available or OpenGL 4.4
Creation:
glGenBuffers(1, &vboID);
glBindBuffer(GL_ARRAY_BUFFER, vboID);
flags = GL_MAP_WRITE_BIT | GL_MAP_PERSISTENT_BIT | GL_MAP_COHERENT_BIT;
glBufferStorage(GL_ARRAY_BUFFER, MY_BUFFER_SIZE, 0, flags);
Mapping (only once after creation…):
flags = GL_MAP_WRITE_BIT | GL_MAP_PERSISTENT_BIT | GL_MAP_COHERENT_BIT;
myPointer = glMapBufferRange(GL_ARRAY_BUFFER, 0, MY_BUFFER_SIZE, flags);
Update:
// wait for the buffer
// just take your pointer (myPointer) and modyfy underlying data...
// lock the buffer
As name suggests, it allows you to map buffer once and keep the pointer forever. At the same time you are left with the synchronization problem
- that’s why there are comments about waiting and locking the buffer in the code above.
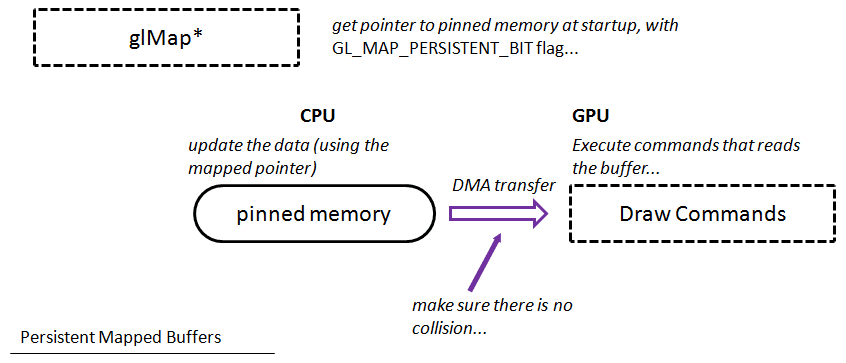
On the diagram you can see that in the first place we need to get a pointer to the buffer memory (but we do it only once), then we can update the data (without any special calls to OpenGL). The only additional action we need to perform is synchronization or making sure that GPU will not read while we write at the same time. All the needed DMA transfers are invoked by the driver.
The GL_MAP_COHERENT_BIT flag makes your changes in the memory
automatically visible to GPU. Without this flag you would have to
manually set a memory barrier. Although, it looks like that
GL_MAP_COHERENT_BIT should be slower than explicit and custom memory
barriers and syncing, my first tests did not show any meaningful
difference. I need to spend more time on that… Maybe you some more
thoughts on that? BTW: even in the original AZDO presentation the
authors mention to use GL_MAP_COHERENT_BIT so this shouldn’t be a
serious problem :)
Syncing
// waiting for the buffer
GLenum waitReturn = GL_UNSIGNALED;
while (waitReturn != GL_ALREADY_SIGNALED && waitReturn != GL_CONDITION_SATISFIED)
{
waitReturn = glClientWaitSync(syncObj, GL_SYNC_FLUSH_COMMANDS_BIT, 1);
}
// lock the buffer:
glDeleteSync(syncObj);
syncObj = glFenceSync(GL_SYNC_GPU_COMMANDS_COMPLETE, 0);
When we write to the buffer we place a sync object. Then, in the following frame we need to wait until this sync object is signaled. In other words, we wait till GPU processes all the commands before setting that sync.
Triple buffering
But we can do better: by using triple buffering we can be sure that GPU and CPU will not touch the same data in the buffer:
- allocate one buffer with 3x of the original size
- map it forever
- bufferID = 0
- update/draw
- update
bufferIDrange of the buffer only - draw that range
bufferID = (bufferID+1)%3
- update
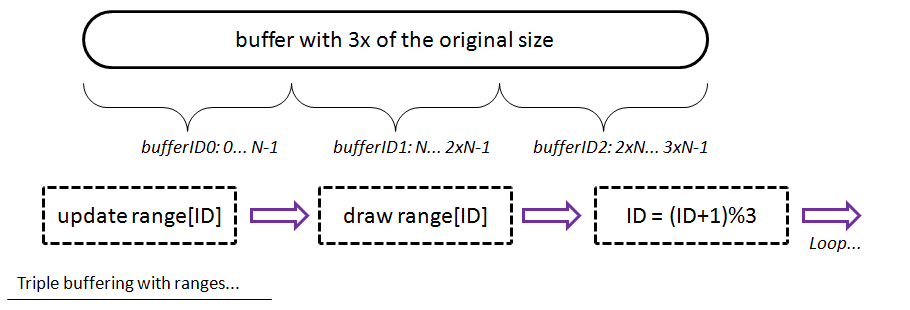
That way, in the next frame you will update another part of the buffer so that there will be no conflict.
Another way would be to create three separate buffers and update them in a similar way.
Demo
![]()
I’ve forked demo application of Ferran Sole’s example and extended it a bit.
Here is the github repo: fenbf/GLSamples
- configurable number of triangles
- configurable number of buffers: single/double/triple
- optional syncing
- optional debug flag
- benchmark mode
- output:
- number of frames
- counter that is incremented each time we wait for the buffer
Full results will be published in the next post: see it here
Summary
This was a long post, but I hope I explained everything in a decent way. We went through standard approach of buffer updates (buffer streaming), saw our main problem: synchronization. Then I’ve described usage of persistence mapped buffers.
Should you use persistent mapped buffers? Here is the short summary about that:
Pros
- Easy to use
- Obtained pointer can be passed around in the app
- In most cases gives performance boost for very frequent buffer
updates (when data comes from CPU side)
- reduces driver overhead
- minimizes GPU stalls
- Advised for AZDO techniques
Drawbacks
- Do not use it for static buffers or buffers that do not require updates from CPU side.
- Best performance with triple buffering (might be a problem when you have large buffers, because you need a lot of memory to allocate).
- Need to do explicit synchronization.
- In OpenGL 4.4, so only latest GPU can support it.
In the next post I’ll share my results from the Demo application. I’ve compared glMapBuffer approach with glBuffer*Data and persistent mapping.
Interesting questions:
- Is this extension better or worse than AMD_pinned_memory?
- What if you forget to sync, or do it in a wrong way? I did not get any apps crashes and hardly see any artifacts, but what’s the expected result of such situation?
- What if you forget to use GL_MAP_COHERENT_BIT? Is there that much performance difference?
References
- [PDF] OpenGL Insights, Chapter 28 - Asynchronous Buffer Transfers by Ladislav Hrabcak and Arnaud Masserann, a free Chapter from [OpenGL Insights].(http://openglinsights.com/)
- Persistent mapped buffers @ferransole.wordpress.com
- Maximizing VBO upload performance! @Java-Gaming.org Forum
- Buffer Object @OpenGL Wiki
- Buffer Object Streaming @OpenGL Wiki
- persistent buffer mapping - what kind of magic is this? @OpenGL Forum
I've prepared a valuable bonus for you!
Learn all major features of recent C++ Standards on my Reference Cards!
Check it out here:
