
Last Update:
Three Benchmarks of C++20 Ranges vs Standard Algorithms
With C++20, we have a new approach to writing algorithms and composing them. The significant question is their performance. Are they faster or slower than the standard C++ algorithms we have known for decades? Let’s find out in this article.
I’ll show you three use cases with performance results, and also we’ll compare build times.
The first case: a pointless test?
I don’t think that comparing std::alg_name with its ranges counterpart like std::ranges::alg_name will give us any difference… but for completeness let’s make a simple sorting test:
static void Standard(benchmark::State& state) {
auto data = words;
for (auto _ : state) {
std::sort(data.begin(), data.end());
benchmark::DoNotOptimize(data);
}
}
BENCHMARK(Standard);
static void Ranges(benchmark::State& state) {
auto data = words;
for (auto _ : state) {
std::ranges::sort(data);
benchmark::DoNotOptimize(data);
}
}
BENCHMARK(Ranges);
Using Quick Bench gives us the exact timings… what a surprise :)
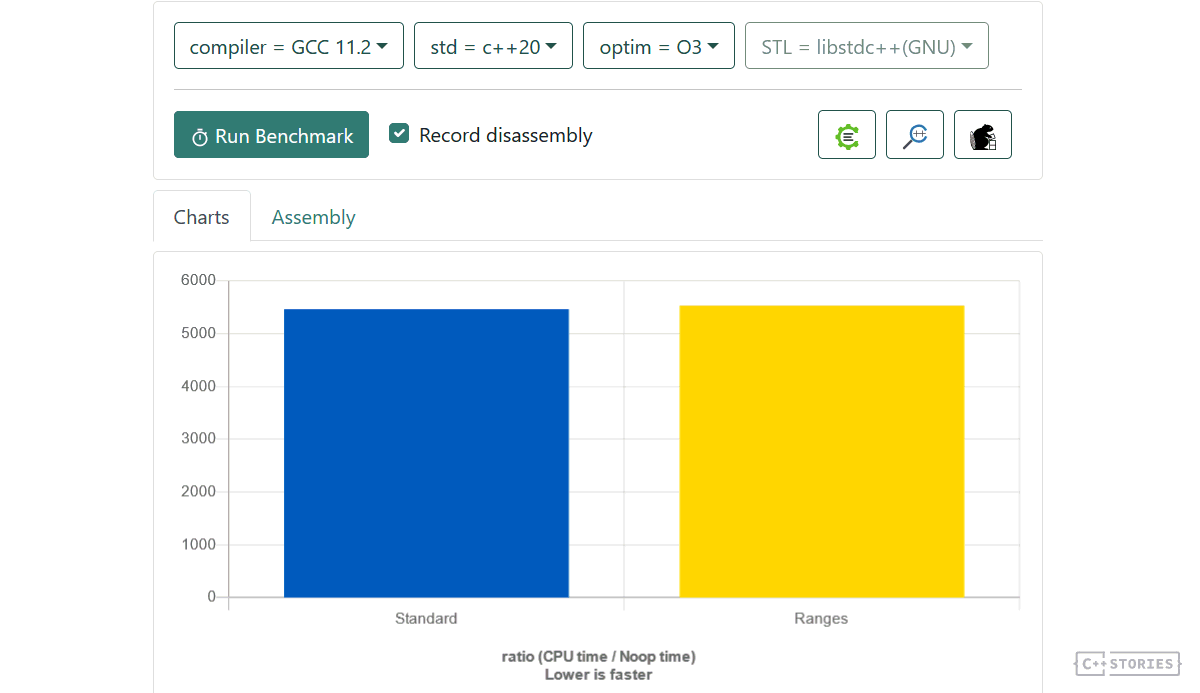
Play @Quick Bench.
As you can see, there might be no significant difference when you compare such simple cases. The ranges algorithms take a whole container (or another range/view) and then perform the computation. So this shouldn’t be any different than passing two iterators in the standard way. Still, ranges offer some extra capabilities like projections - C++20 Ranges, Projections, std::invoke and if constexpr - C++ Stories.
When we compare build times, we can see that the ranges version is only 10% slower (compiling both in C++20 mode)
See @Build Bench
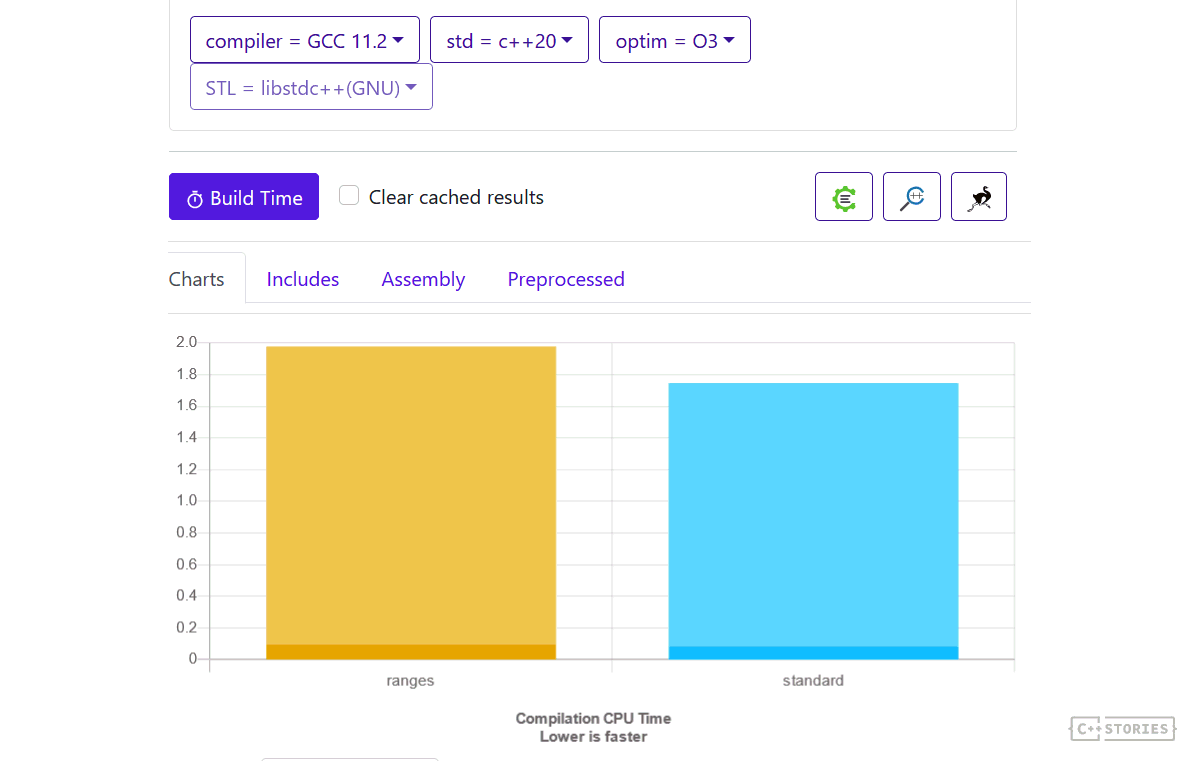
Build times are also not the best measurement here. My tests are pretty simple and represent only 10…100 LOC. So if your project is large, then adding ranges might not add 10% like in my example… but maybe 1% or even less. Various factors might affect the results.
Interesting benchmark: when I set C++17 as the compilation mode for the standard std::sort, the ranges version was 1.8x slower to compile! See here: @Build Bench.
How about algorithm composition and more complex cases? I have two examples: string trim and then string split.
The second case: trimming a string
Let’s compare the first algorithm:
std::string trimLeft(const std::string &s) {
auto temp = s;
temp.erase(std::begin(temp),
std::find_if_not(std::begin(temp), std::end(temp), isspace));
return temp;
}
std::string trimRight(const std::string &s) {
auto temp = s;
temp.erase(std::find_if_not(std::rbegin(temp), std::rend(temp), isspace).base(),
std::end(temp));
return temp;
}
std::string trim(const std::string &s) {
return trimLeft(trimRight(s));
}
The final trim function composes of two parts: left and right. If you look closer, you can see that we have an extra copy of the string object, so let’s create a more optimal way:
std::string trim2(const std::string &s) {
auto wsfront=std::find_if_not(s.begin(),s.end(), isspace);
auto wsback=std::find_if_not(s.rbegin(),s.rend(), isspace).base();
return (wsback<=wsfront ? std::string() : std::string(wsfront,wsback));
}
And now the ranges version (found at SO: c++ - Can trim of a string be done inplace with C++20 ranges? - Stack Overflow)
std::string trimRanges(const std::string &s) {
auto viewWord {s |
std::views::drop_while(isspace) |
std::views::reverse |
std::views::drop_while(isspace) |
std::views::reverse};
return std::string(begin(viewWord), end(viewWord));
}
We can also check another version for ranges, that looks similar to trim2:
std::string trimRanges2(const std::string &s) {
auto wsfront=std::ranges::find_if_not(s, isspace);
auto wsback=std::ranges::find_if_not(s | std::views::reverse, isspace).base();
return (wsback<=wsfront ? std::string() : std::string(wsfront,wsback));
}
We can now build a test:
- prepare a list of words
- add some spaces before and after the input word
- run tests for
trim - run tests for
trim2 - run tests for
trimRanges - run tests for
trimRanges2
Here’s the core code for the experiment:
int main() {
const std::vector<std::string> words { /*...*/ };
auto spacedWords = AddSpaces(words);
const size_t iters = 100;
RunAndMeasure("ranges", [&spacedWords, &words, iters](){
std::vector<std::string> out;
out.reserve(spacedWords.size() * iters);
for (size_t i = 0; i < iters; ++ i) {
for (auto& w : spacedWords)
out.emplace_back(trimRanges(w));
}
return std::ranges::equal(out | std::views::take(words.size()), words);
});
RunAndMeasure("ranges2", [&spacedWords, &words, iters](){
std::vector<std::string> out;
out.reserve(spacedWords.size() * iters);
for (size_t i = 0; i < iters; ++ i) {
for (auto& w : spacedWords)
out.emplace_back(trimRanges2(w));
}
return std::ranges::equal(out | std::views::take(words.size()), words);
});
RunAndMeasure("standard", [&spacedWords, &words, &iters](){
std::vector<std::string> out;
out.reserve(spacedWords.size()*iters);
for (size_t i = 0; i < iters; ++ i) {
for (auto& w : spacedWords)
out.emplace_back(trim(w));
}
return std::ranges::equal(out | std::views::take(words.size()), words);
});
RunAndMeasure("standard 2", [&spacedWords, &words, &iters](){
std::vector<std::string> out;
out.reserve(spacedWords.size()*iters);
for (size_t i = 0; i < iters; ++ i) {
for (auto& w : spacedWords)
out.emplace_back(trim2(w));
}
return std::ranges::equal(out | std::views::take(words.size()), words);
});
}
Run the complete example @Compiler Explorer
On CE, I got the following results:
ranges: 0.404869 ms
ranges 2: 0.338989 ms
standard: 0.486914 ms
standard 2: 0.250221 ms
Here’s the full benchmark using google-benchmark library @Quick Bench:
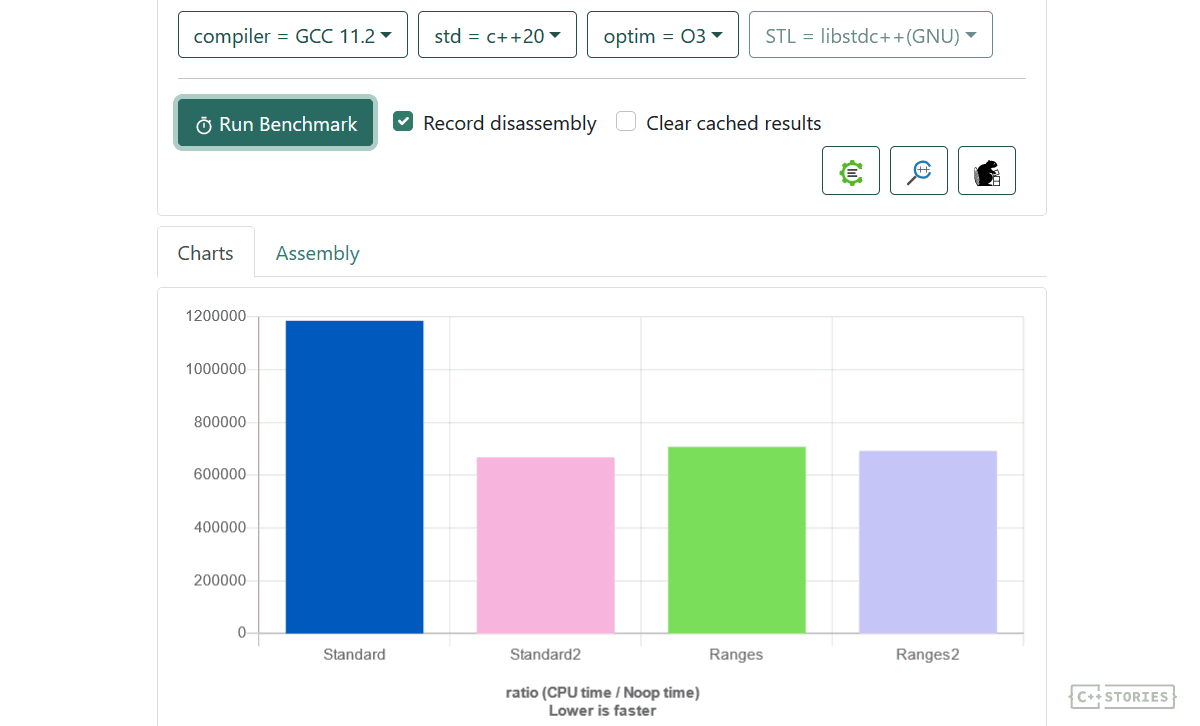
It looks like the standard 2 version (without the temporary) is the fastest way, and it’s probably one of the easiest ways to implement this problem.
The third case: string split
Let’s take some other algorithm: splitting a string.
This problem is interesting as there’s no single standard algorithm from the Standard Library, and we need to write some code to implement it.
For the standard version, I took implementation from my experiment: Speeding Up string_view String Split Implementation - C++ Stories
Here’s the code:
std::vector<std::string_view>
splitSVPtr(std::string_view str, std::string_view delims)
{
std::vector<std::string_view> output;
for (auto first = str.data(), second = str.data(), last = first + str.size();
second != last && first != last; first = second + 1)
{
second = std::find_first_of(first, last, std::cbegin(delims), std::cend(delims));
if (first != second)
output.emplace_back(first, second - first);
}
return output;
}
And the corresponding ranges version where we use a single view:
std::vector<std::string_view> rangesSplitSV(std::string_view str, std::string_view delims = " ")
{
std::vector<std::string_view> output;
for (const auto word : std::views::split(str, delims))
output.emplace_back(word.begin(), word.end());
return output;
}
Here we can use ranges::views::split, which is an optimized split view that comes from P2210R2 - Superior String Splitting (a Defect Report against C++20, and not all libraries/compilers have it though). We also have lazy_split, which might give a bit worse performance and usage…
Here’s a link to my test using Compiler Explorer (as quick-bench doesn’t have the latest GCC with P2210), and here are the results:
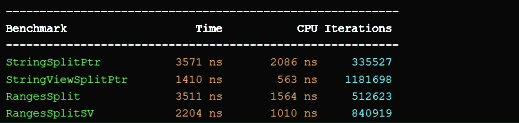
And another run on my machine and MSVC 2022:
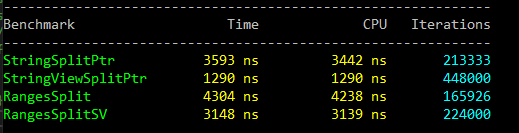
The output shows four algorithms and two groups. There’s StringSplitPtr and RangesSplit - they return a vector of std::string objects. While StringViewSplitPtr and RangesSplitSV returns a vector of string_view objects. Working with string views yields faster computation as there’s no need to copy data to a separate string.
It looks like the standard version is faster than Ranges in both machines and compiler.
Summary
Measure, measure, measure :)
In this article, I showed only three cases: the first one with sorting didn’t show any differences between ranges and standard algorithms. But the two other examples visualized a potential loss against the “old” library counterparts - the composed ranges algorithms were a bit slower.
Have you played with ranges? Have you seen any performance issues? Share your opinion and experience in the comments below the article. Have you started using ranges? What’s your initial experience? Let us know in the comments below the article.
You can also look at other benchmarks:
- How to convert std::vector to a vector of pairs std::vector<std::pair<T,T» using STL algorithm? - by Kobi - comparison with ranges-v3, ranges are faster than the standard version, and only a bit slower than the plain manual version.
- Performance benchmark: Ranges VS STL algorithms VS Smart output iterators - Fluent C++ - Jonathan shows various cases against Ranges-V3.
I've prepared a valuable bonus for you!
Learn all major features of recent C++ Standards on my Reference Cards!
Check it out here:

Similar Articles:
- 20 Smaller yet Handy C++20 Features
- Examples of 7 Handy Functions for Associative Containers in Modern C++
- Empty Base Class Optimisation, no_unique_address and unique_ptr
- Increased Complexity of C++20 Range Algorithms Declarations - Is It Worth it?
- Polymorphic Allocators, std::vector Growth and Hacking