
Last Update:
Google benchmark library

Table of Contents
Some time ago I wrote about micro benchmarking libraries for C++ - here’s the link. I’ve described three libraries: Nonius, Hayai, Celero. But actually, I wanted to cover fourth one. Google Benchmark library was at that time not available for my Windows environment, so I couldn’t test it. Fortunately, under the original post I got a comment saying that the library is now ready for Visual Studio!
Let’s see how can we use it.
The library
Main github repo:
github/google/benchmark
Discussion group:
groups.google/forum/benchmark-discuss
Thanks to KindDragon commit: Support MSVC on appveyor we can now build the library under Visual Studio. Without any problems I was able to download the latest repo, use CMake to generate solution files, then build a proper version. To use it with your project, all you have to do is to link to the library itself and include one header file.
Simple example
In the original article I’ve used two experiments:
IntToStringConversionTest(count)- converts numbers 0…count-1 into a string and return vector of it.DoubleToStringConversionTest(count)- converts numbers 0.12345… count-1+0.12345 into a string and then return vector of those strings.
The full example of benchmarks:
#include "benchmark/benchmark_api.h"
#include "../commonTest.h"
void IntToString(benchmark::State& state) {
while (state.KeepRunning()) {
benchmark::DoNotOptimize(
IntToStringConversionTest(state.range_x())
);
}
}
BENCHMARK(IntToString)->Arg(TEST_NUM_COUNT1000);
void DoubleToString(benchmark::State& state) {
while (state.KeepRunning()) {
benchmark::DoNotOptimize(
DoubleToStringConversionTest(state.range_x())
);
}
}
BENCHMARK(DoubleToString)->Arg(TEST_NUM_COUNT1000);
BENCHMARK_MAIN()
Nice and simple! BENCHMARK macro is used to define a benchmark, then
you can add invocation params. In the example above I’ve used Arg
method. The parameter inside that method will be passed into the state
object that is available to the benchmark function. In our example we
can fetch the value as state.range_x(). This value is then translated
into the size of the numbers vector.
Inside the benchmark function there is a while loop where the main code is executed. The library will automatically set the number of iterations.
As usually the application can be run in console mode with the following
result:

We get a really simple output: benchmark name, time in nanoseconds (can
be changed through Unit() method), CPU time, iterations invoked.
What are the nice features of the library?
- Easy passing of custom values: Arg, ArgPair, Range, RangePair,
Apply.
- Values can be fetched as
state.get_x(),state.get_y() - So you can create one or two dimensional problem space benchmarks.
- Values can be fetched as
- Fixtures
- Multithreaded benchmarks
- Manual timing: useful when you execute code on GPU or other devices where standard CPU timing is not relevant.
- Output formats: tabular, CSV, Json
- Ability to insert custom label through
state.SetLabel() - Labels for items processed and bytes processed thanks to
state.SetItemsProcessed()andstate.SetBytesProcessed()
Another output: with bytes processed, items processed, custom label and
changed time units.

Advanced example
In the another post about micro benchmarking libraries I’ve used a bit more advanced example to test benchmark libraries. It’s my standard benchmark - vector of pointers vs vector of objects. Let’s see how can we implement that experiment with Google Benchmark.
Setup
What we’re going to test:
- Particle class: holds 18 floats: 4 for pos, 4 for vel, 4 for
acceleration, 4 for color, one for time, one for rotation. Plus
there is a float buffer - we can change number of elements in that
buffer.
- Basic particle is 76 bytes
- Larger particle is defined for 160 bytes.
- We want to measure Update method on a vector of particles.
- Five kind of containers:
vector<Particle>vector<shared_ptr<Particle>>- randomized mem locationvector<shared_ptr<Particle>>- not randomized mem locationvector<unique_ptr<Particle>>- randomized mem locationvector<unique_ptr<Particle>>- not randomized mem location
Some code
Example code for vector<Particle:
template <class Part>
class ParticlesObjVectorFixture : public ::benchmark::Fixture {
public:
void SetUp(const ::benchmark::State& st) {
particles = std::vector<Part>(st.range_x());
for (auto &p : particles)
p.generate();
}
void TearDown(const ::benchmark::State&) {
particles.clear();
}
std::vector<Part> particles;
};
And the benchmark:
using P76Fix = ParticlesObjVectorFixture<Particle>;
BENCHMARK_DEFINE_F(P76Fix, Obj)(benchmark::State& state) {
while (state.KeepRunning()) {
UpdateParticlesObj(particles);
}
}
BENCHMARK_REGISTER_F(P76Fix, Obj)->Apply(CustomArguments);
using P160Fix = ParticlesObjVectorFixture<Particle160>;
BENCHMARK_DEFINE_F(P160Fix, Obj)(benchmark::State& state) {
while (state.KeepRunning()) {
UpdateParticlesObj(particles);
}
}
BENCHMARK_REGISTER_F(P160Fix, Obj)->Apply(CustomArguments);
With the above code we test for two kinds of particles: smaller - 76
bytes abd larger - 160 bytes. CustomArguments method generate number
of particles in each benchmark invocation: 1k, 3k, 5k, 7k, 9k, 11k.
Results
In this blog post we focus on the library itself, but I wanted to cover one thing that was asked in the past: different size of a particle. I used only two kinds for now: 76 bytes and 160 bytes.
Results for 76 bytes:
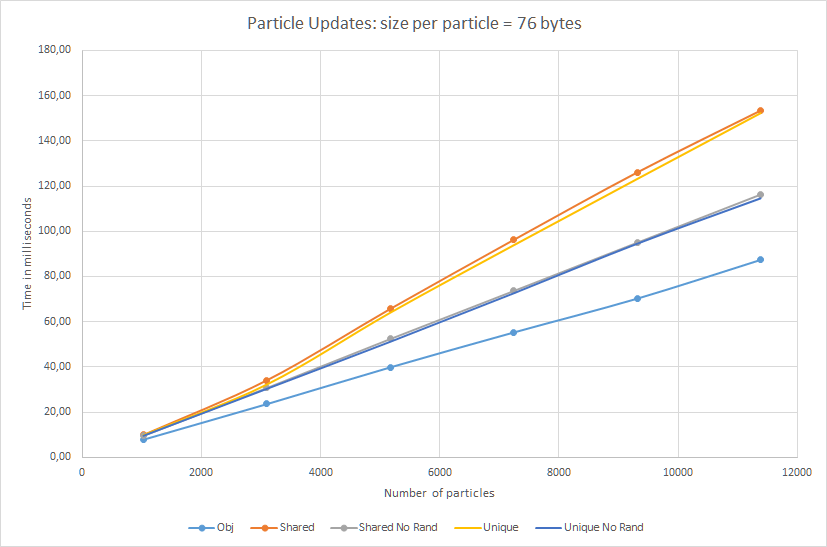
Randomized pointers are almost 76% slower than vector of objects.
Results for 160 bytes:
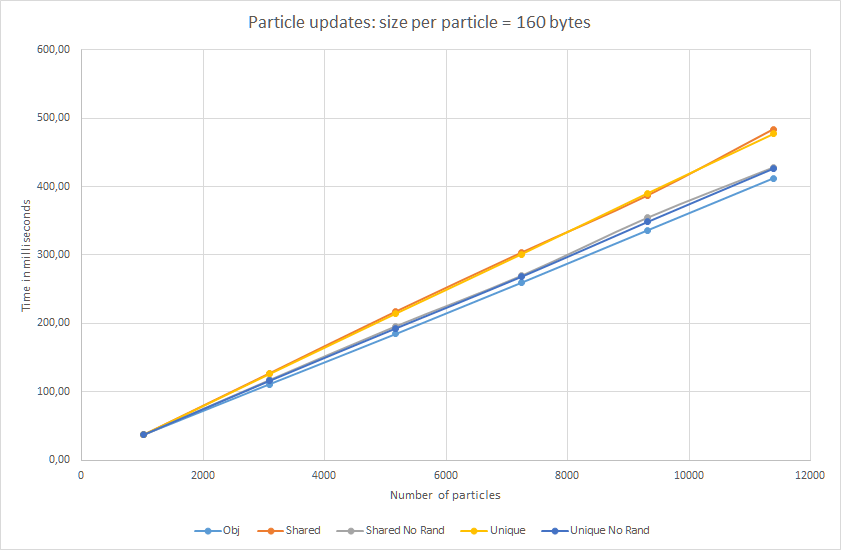
Almost straight lines for the larger case! Randomized pointers are only 17% slower…. ok, so maybe not completely straight :)
Additionally, unique_ptr is also tested. And, as you can see, in terms
of updates (access to the data) the speed is almost the same as for
shared_ptr. The indirection is the problem and not the overhead of the
smart pointer.
Summary
Repo with the code samples: github/fenbf/benchmarkLibsTest
I had no problems with using Google Benchmark library. In several
minutes you can grasp style of building benchmarks. Multithreaded
benchmarks, fixtures, automatic iteration estimation, CSV, or Json
output formats, those are all solid features. I especially liked
flexibility of passing parameters to the benchmark code. Other libraries
that I’ve tested had some problems with passing a ‘problem space’ values
into benchmark code. Celero was the easiest on in that area.
What’s missing for me is the lack of advanced results. The library
provides only a mean time of the iterations. Still, in most cases that’s
good enough.
In terms of the experiment: I got interesting results when measuring different size per particle. It’s a good base for the final future test. I’ll try to recreate my examples again with more diversity of object size. I expect to see a huge difference when the object is small, and small difference when the object is large.
I've prepared a valuable bonus for you!
Learn all major features of recent C++ Standards on my Reference Cards!
Check it out here:
