
Last Update:
How to Parallelise CSV Reader - C++17 in Practice

Table of Contents
At C++Stories (and in my C++17 book) you can find several articles on Parallel Algorithms introduced in C++17. The examples included in those posts were usually relatively straightforward. How about writing something larger?
In this text, you’ll see how to build a tool that works on CSV files, parses lines into sales records and then performs calculations on the data.
You’ll see how easy it is to add parallel execution to selected algorithms and have a performance improvement across the whole application (for example 4.5x on 6 cores, including file loading). In the end, we’ll discuss problems that we found along the way and possible future enhancements.
Here’s the plan:
- How to build an application that loads CSV files
- How to efficiently use parallel algorithms
- How to use
std::filesystemlibrary to gather required files - How to use other C++17 library features like
std::optional, conversion routines -std::from_charsandstring_view - Where to add
[[nodiscard]]and improve code readability
Let’s go.
This article is an excerpt from my book: "C++17 in Detail".
Get the Ebook here at @Leanpub, or the print version @Amazon. And join almost 3000 readers!
Also, have a look at the Anniversary Promo at the end of the article :)
Introduction and Requirements
Imagine you’re working with some sales data and one task is to calculate a sum of orders for some products. Your shopping system is elementary, and instead of a database, you have CSV files with the order data. There’s one file per product.
Take this example of book sales:
| date | coupon code | price | discount | quantity |
|---|---|---|---|---|
| 5-08-2021 | 10.0 | 0 | 2 | |
| 5-08-2021 | 10.0 | 0 | 1 | |
| 6-08-2021 | Summer | 10.0 | 0.25 | 1 |
| 7-08-2021 | 10.0 | 0 | 1 |
Each line shows a book sale on a specific date. For example, 5th Aug there were three sales, 10$ each, and one person bought two books. On 6th Aug we had one transaction with a coupon code.
The data is encoded as a CSV file: sales/book.csv:
5-08-2021;;10.0;0;2;
5-08-2021;;10.0;0;1;
6-08-2021;Summer;10.0;0.25;1;
7-08-2021;;10.0;0;1;
The application should read the data and then calculate the sum, so in the above case we have
sum = 10*2+10*1+ // 5th Aug
10*(1-0.25)*1 + // 6th Aug with 25% coupon
10*1; // 7th Aug
For the above sales data, the final sum is 47.5$.
Here are the requirements of the application we want to build:
- The application loads all CSV files in a given folder - read from the first argument in the command line
- The files might contain thousands of records but will fit into memory. There’s no need to provide extra support for huge files
- Optionally, the application reads the start and end dates from the second and the third command-line argument
- Each CSV line has the following structure:
date;coupon code;unit price;quantity;discount;
- The application sums all orders between given dates and prints the sum to the standard output
We’ll implement the serial version first, and then we’ll try to make it parallel.
The Serial Version
For the first step, we’ll cover a serial version of the application. This allows you to understand the core parts of the system and see how the tool works.
The code doesn’t fit easily on a single page so you can have a look at it in the following file:
github.com/fenbf/articles/cpp17/CSV%20Reader/csv_reader.cpp
In the next sections, we’ll explore the core parts of the application.
The Main
Let’s start with the main() function.
|
|
Once we’re sure that there are enough arguments in the command line, we enter the main scope where all the processing happens:
- line 6 - gather all the files to process - in
CollectPaths() - line 16 - convert data from the files into record data and calculate the results - in
CalcResults() - line 18 - show the results on the output - in
ShowResults()
The code relies on exceptions across the whole application.
The paths are collected using directory_iterator from the std::filesystem library:
bool IsCSVFile(const fs::path &p) {
return fs::is_regular_file(p) && p.extension() == CSV_EXTENSION;
}
[[nodiscard]] std::vector<fs::path> CollectPaths(const fs::path& startPath) {
std::vector<fs::path> paths;
fs::directory_iterator dirpos{ startPath };
std::copy_if(fs::begin(dirpos), fs::end(dirpos), std::back_inserter(paths),
IsCSVFile);
return paths;
}
As in other filesystem examples, the namespace fs is an alias for std::filesystem.
With directory_iterator we can easily iterate over a given directory. By using copy_if, we can filter out unwanted files and select only those with a CSV extension. Notice how easy it is to get the elements of the path and check files’ properties.
Going back to main(), we check if there are any files to process (line 8).
Then, in lines 13 and 14, we parse the optional dates: startDate and endDate are read from argv[2] and argv[3].
The dates are stored in a helper class Date that lets you convert from strings with a simple format of Day-Month-Year or Year-Month-Day.
The class also supports comparison of dates.
This will help us check whether a given order fits between selected dates.
Now, all of the computations and printouts are contained in lines:
const auto results = CalcResults(paths, startDate, endDate);
ShowResults(results, startDate, endDate);
CalcResults() implements the core requirements of the application:
- converting data from the file into a list of records to process
- calculating a sum of records between given dates
struct Result {
std::string mFilename;
double mSum{ 0.0 };
};
[[nodiscard]] std::vector<Result>
CalcResults(const std::vector<fs::path>& paths, Date startDate, Date endDate) {
std::vector<Result> results;
for (const auto& p : paths) {
const auto records = LoadRecords(p);
const auto totalValue = CalcTotalOrder(records, startDate, endDate);
results.push_back({ p.string(), totalValue });
}
return results;
}
The code loads records from each CSV file, then calculates the sum of those records. The results (along with the name of the file) are stored in the output vector.
We can now reveal the code behind the two essential methods LoadRecords and CalcTotalOrder.
Converting Lines into Records
LoadRecords is a function that takes a filename as an argument, reads the contents into std::string and then performs the conversion:
[[nodiscard]] std::vector<OrderRecord> LoadRecords(const fs::path& filename) {
const auto content = GetFileContents(filename);
const auto lines = SplitLines(content);
return LinesToRecords(lines);
}
We assume that the files are small enough to fit into RAM, so there’s no need to process them in chunks.
The core task is to split that one large string into lines and then convert them into a collection of Records.
If you look into the code, you can see that content is std::string, but lines is a vector of std::string_view.
Views are used for optimisation. We guarantee to hold the large string - the file content - while we process chunks of it (views).
This should give us better performance, as there’s no need to copy string data.
Eventually, characters are converted into OrderRecord representation.
The OrderRecord Class
The main class that is used to compute results is OrderRecord. It’s a direct representation of a line from a CSV file.
class OrderRecord {
public:
// constructors...
double CalcRecordPrice() const noexcept;
bool CheckDate(const Date& start, const Date& end) const noexcept;
private:
Date mDate;
std::string mCouponCode;
double mUnitPrice{ 0.0 };
double mDiscount{ 0.0 }; // 0... 1.0
unsigned int mQuantity{ 0 };
};
The conversion
Once we have lines we can convert them one by one into objects:
[[nodiscard]] std::vector<OrderRecord>
LinesToRecords(const std::vector<std::string_view>& lines) {
std::vector<OrderRecord> outRecords;
std::transform(lines.begin(), lines.end(),
std::back_inserter(outRecords), LineToRecord);
return outRecords;
}
The code above is just a transformation, it uses LineToRecord to do the hard work:
[[nodiscard]] OrderRecord LineToRecord(std::string_view sv) {
const auto cols = SplitString(sv, CSV_DELIM);
if (cols.size() == static_cast<size_t>(OrderRecord::ENUM_LENGTH)) {
const auto unitPrice = TryConvert<double>(cols[OrderRecord::UNIT_PRICE]);
const auto discount = TryConvert<double>(cols[OrderRecord::DISCOUNT]);
const auto quantity = TryConvert<unsigned int>(cols[OrderRecord::QUANTITY]);
if (unitPrice && discount && quantity) {
return { Date(cols[OrderRecord::DATE]),
std::string(cols[OrderRecord::COUPON]),
*unitPrice,
*discount,
*quantity };
}
}
throw std::runtime_error("Cannot convert Record from " + std::string(sv));
}
Firstly, the line is split into columns, and then we can process each column.
If all elements are converted, then we can build a record.
For conversions of the elements we’re using a small utility based on std::from_chars:
template<typename T>
[[nodiscard]] std::optional<T> TryConvert(std::string_view sv) noexcept {
T value{ };
const auto last = sv.data() + sv.size();
const auto res = std::from_chars(sv.data(), last, value);
if (res.ec == std::errc{} && res.ptr == last)
return value;
return std::nullopt;
}
TryConvert uses std::from_chars and returns a converted value if there are no errors. As you remember, to guarantee that all characters were parsed, we also have to check res.ptr == last. Otherwise, the conversion might return success for input like “123xxx”.
Calculations
Once all the records are available we can compute their sum:
[[nodiscard]] double CalcTotalOrder(const std::vector<OrderRecord>& records,
const Date& startDate, const Date& endDate) {
return std::accumulate(std::begin(records), std::end(records), 0.0,
[&startDate, &endDate](double val, const OrderRecord& rec) {
if (rec.CheckDate(startDate, endDate))
return val + rec.CalcRecordPrice();
else
return val;
}
);
}
The code runs on the vector of all records and then calculates the price of each element if they fit between startDate and endDate. Then they are all summed in std::accumulate.
Design Enhancements
The application calculates only the sum of orders, but we could think about adding other things. For example, minimal value, maximum, average order and other statistics.
The code uses a simple approach, loading a file into a string and then creating a temporary vector of lines. We could also enhance this by using a line iterator. It would take a large string and then return a line when you iterate.
Another idea relates to error handling. For example, rather than throwing exceptions, we could enhance the conversion step by storing the number of successfully processed records.
Running the Code
The application is ready to compile, and we can run it on the example data shown in the introduction.
CSVReader.exe sales/
This should read a single file sales/book.csv and sum up all the records (as no dates were specified):
.\CalcOrdersSerial.exe .\sales\
Name Of File | Total Orders Value
sales\book.csv | 47.50
CalcResults: 3.13 ms
CalcTotalOrder: 0.01 ms
Parsing Strings: 0.01 ms
The full version of the code also includes timing measurement, so that’s why you can see that the operation took around 3ms to complete. The file handling took the longest; calculations and parsing were almost immediate.
In the next sections, you’ll see a few simple steps you can take to apply parallel algorithms.
Using Parallel Algorithms
Previously the code was executed sequentially. We can illustrate it in the following diagram:
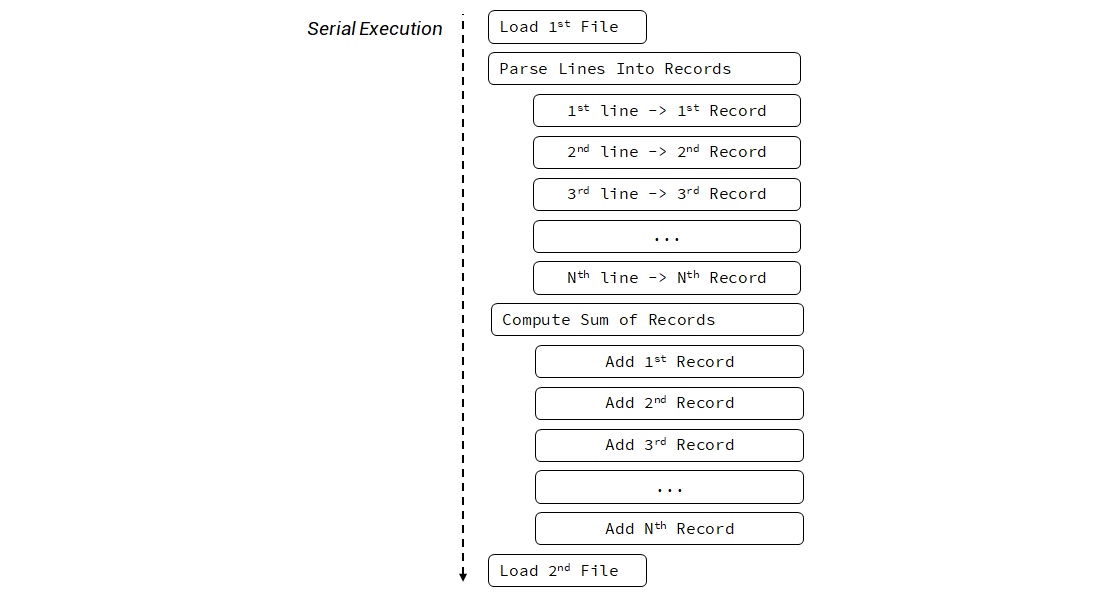
We open each file, process it, calculate, then we go to another file. All this happens on a single thread.
However, there are several places we can consider using parallel algorithms:
- Where each file can be processed separately
- Where each line of a file can be converted independently into the Record Data
- Where calculations can be enhanced with parallel execution
If we focus on the second and the third options, we can move into the following execution model:
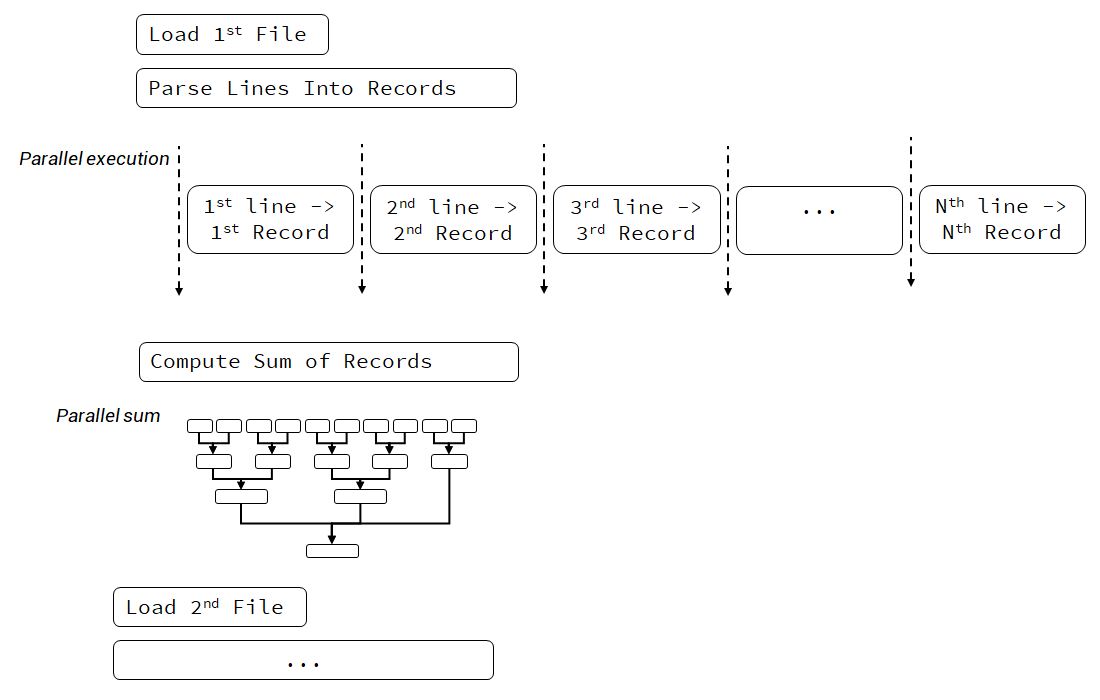
The above diagram shows that we’re still processing file one by one, but we use parallel execution while parsing the strings and making the calculations.
When doing the conversion, we have to remember that exceptions won’t be re-thrown from our code. Only std::terminate will be called.
Data Size & Instruction Count Matters
How to get the best performance with parallel algorithms?
You need two things:
- a lot of data to process
- instructions to keep the CPU busy
We also have to remember one rule:
In general, parallel algorithms do more work, as they introduce the extra cost of managing the parallel execution framework as well as splitting tasks into smaller batches.
First and foremost, we have to think about the size of the data we’re operating on. If we have only a few files, with a few dozen records, then we may not gain anything with parallel execution. But if we have lots of files, with hundreds of lines each, then the potential might increase.
The second thing is the instruction count. CPU cores need to compute and not just wait on memory. If your algorithms are memory-bound, then parallel execution might not give any speed-up over the sequential version. In our case, it seems that the parsing strings task is a good match here. The code performs searching on strings and does the numerical conversions, which keeps CPU busy.
Parallel Data Conversion
As previously discussed, we can add parallel execution to the place where we convert the data. We have lots of lines to parse, and each parsing is independent.
[[nodiscard]] std::vector<OrderRecord>
LinesToRecords(const std::vector<std::string_view>& lines) {
std::vector<OrderRecord> outRecords(lines.size());
std::transform(std::execution::par, std::begin(lines), std::end(lines),
std::begin(outRecords), LineToRecord);
return outRecords;
}
Two things need to be changed to the serial version:
- we need to preallocate the vector
- we have to pass
std::execution::par(orpar_unseq) as the first argument
The serial code also used std::transform, so why cannot we just pass the execution parameter?
We can even compile it… but you should see an error like:
Parallel algorithms require forward iterators or stronger.
The reason is simple: std::back_inserter is very handy, but it’s not a forward iterator.
It inserts elements into the vector, and that causes a vector to be changed (reallocated) by multiple threads.
All of the insertions would have to be guarded by some critical section, and thus the overall performance could be weak.
Since we need to preallocate the vector, we have to consider two things:
- we pay for default construction of objects inside a vector, which probably isn’t a big deal when objects are relatively small, and their creation is fast.
- on the other hand, the vector is allocated once, and there’s no need to grow it (copy, reallocate) as in the case of
std::back_inserter.
Parallel Calculations
Another place where we can leverage parallel algorithms is CalcTotalOrder().
Instead of std::accumulate we can use std::transform_reduce.
Note: The floating-point sum operation is not associative and since
std::*_reducecomputes the sum in unspecified order, the results might be not “stable”. However, in our case, the results should be stable enough to give 2 decimal places of precision. If you need better accuracy and numerical stability, you may be better off using a different method.
double CalcTotalOrder(const std::vector<OrderRecord>& records,
const Date& startDate, const Date& endDate) {
return std::transform_reduce(
std::execution::par,
std::begin(records), std::end(records),
0.0,
std::plus<>(),
[&startDate, &endDate](const OrderRecord& rec) {
if (rec.CheckDate(startDate, endDate))
return rec.CalcRecordPrice();
return 0.0;
}
);
}
We use the transform step of std::transform_reduce to “extract” values to sum. We cannot easily use std::reduce as it would require us to write a reduction operation that works with two OrderRecord objects.
Tests
We can run the two versions on a set of files and compare if the changes brought any improvements in the performance. The application was tested on a 6 core/12 thread PC - i7 8700, with a fast SSD drive, Windows 10.
Note: Our applications access files, so it’s harder to make accurate benchmarks as we can quickly end up in the file system cache. Before major runs of applications, a tool called Use SysInternal’s RAMMap app is executed to remove files from the cache. There are also Hard Drive hardware caches which are harder to release without a system reboot.
Mid Size Files 1k Lines 10 Files
Let’s start with 10 files, 1k lines each. Files are not in the OS cache:
| Step | Serial (ms) | Parallel (ms) |
|---|---|---|
| All steps | 74.05 | 68.391 |
CalcTotalOrder |
0.02 | 0.22 |
| Parsing Strings | 7.85 | 2.82 |
The situation when files are in the system cache:
| Step | Serial (ms) | Parallel (ms) |
|---|---|---|
| All steps | 8.59 | 4.01 |
CalcTotalOrder |
0.02 | 0.23 |
| Parsing Strings | 7.74 | 2.73 |
The first numbers - 74ms and 68ms - come from reading uncached files, while the next two runs were executed without clearing the system cache so you can observe how much speed-up you get by system caches.
The parallel version still reads files sequentially, so we only get a few milliseconds of improvement. Parsing strings (line split and conversion to Records) is now almost 3x faster. The sum calculations are not better as a single-threaded version seem to handle sums more efficiently.
Large Set 10k Lines in 10 Files
How about larger input?
Uncached files:
| Step | Serial (ms) | Parallel (ms) |
|---|---|---|
| All steps | 239.96 | 178.32 |
CalcTotalOrder |
0.2 | 0.74 |
| Parsing Strings | 70.46 | 15.39 |
Cached:
| Step | Serial (ms) | Parallel (ms) |
|---|---|---|
| All steps | 72.43 | 18.51 |
CalcTotalOrder |
0.33 | 0.67 |
| Parsing Strings | 70.46 | 15.56 |
The more data we process, the better our results. The cost of loading uncached files “hides” slowly behind the time it takes to process the records. In the case of 10k lines, we can also see that the parsing strings step is 3.5 times faster; however, the calculations are still slower.
Largest Set 100k Lines in 10 Files
Let’s do one more test with the largest files:
Uncached files:
| Step | Serial (ms) | Parallel (ms) |
|---|---|---|
| All steps | 757.07 | 206.85 |
CalcTotalOrder |
3.03 | 2,47 |
| Parsing Strings | 699.54 | 143.31 |
Cached:
| Step | Serial (ms) | Parallel (ms) |
|---|---|---|
| All steps | 729.94 | 162.49 |
CalcTotalOrder |
3.05 | 2.16 |
| Parsing Strings | 707.34 | 141.28 |
In a case of large files (each file is ~2MB), we can see a clear win for the parallel version.
Wrap up & Discussion
The main aim of this chapter was to show how easy it is to use parallel algorithms.
The final code is located in two files:
- github.com/fenbf/articles/cpp17/CSV%20Reader/csv_reader.cpp - the serial version
- github.com/fenbf/articles/cpp17/CSV%20Reader/csv_reader_par.cpp - the parallel version
In most of the cases, all we have to do to add parallel execution is to make sure there’s no synchronisation required between the tasks and, if we can, provide forward iterators.
That’s why when doing the conversion we sometimes needed to preallocate std::vector (or other compliant collections) rather than using std::back_inserter.
Another example is that we cannot iterate in a directory in parallel, as std::filesystem::directory_iterator is not a forward iterator.
The next part is to select the proper parallel algorithm. In the case of this example, we replaced std::accumulate with std::transform_reduce for the calculations. There was no need to change std::transform for doing the string parsing - as you only have to use the extra execution policy parameter.
Our application performed a bit better than the serial version. Here are some thoughts we might have:
- Parallel execution needs independent tasks. If you have jobs that depend on each other, the performance might be lower than the serial version! This happens due to extra synchronisation steps.
- Your tasks cannot be memory-bound, otherwise CPU will wait for the memory. For example, the string parsing code performed better in parallel as it has many instructions to execute: string search, string conversions.
- You need a lot of data to process to see the performance gain. In our case, each file required several thousands of lines to show any gains over the sequential version.
- Sum calculations didn’t show much improvement and there was even worse performance for smaller input. This is because the
std::reducealgorithm requires extra reduction steps, and also our calculations were elementary. It’s possible that, with more statistical computations in the code, we could improve performance. - The serial version of the code is straightforward and there are places where extra performance could be gained. For example, we might reduce additional copies and temporary vectors. It might also be good to use
std::transform_reducewith sequential execution in the serial version, as it might be faster thanstd::accumulate. You might consider optimising the serial version first and then making it parallel. - If you rely on exceptions then you might want to implement a handler for
std::terminate, as exceptions are not re-thrown in code that is invoked with execution policies.
Putting it all together, we can draw the following summary:
Parallel algorithms can bring extra speed to the application, but they have to be used wisely. They introduce an additional cost of parallel execution framework, and it’s essential to have lots of tasks that are independent and good for parallelisation. As always, it’s important to measure the performance between the versions to be able to select the final approach with confidence.
Are there any other options to improve the project? Let’s see a few other possibilities on the next page.
Additional Modifications and Options
The code in the parallel version skipped one option: parallel access to files. So far we read files one by one, but how about reading separate files from separate threads?
Here’s a diagram that illustrates this option:
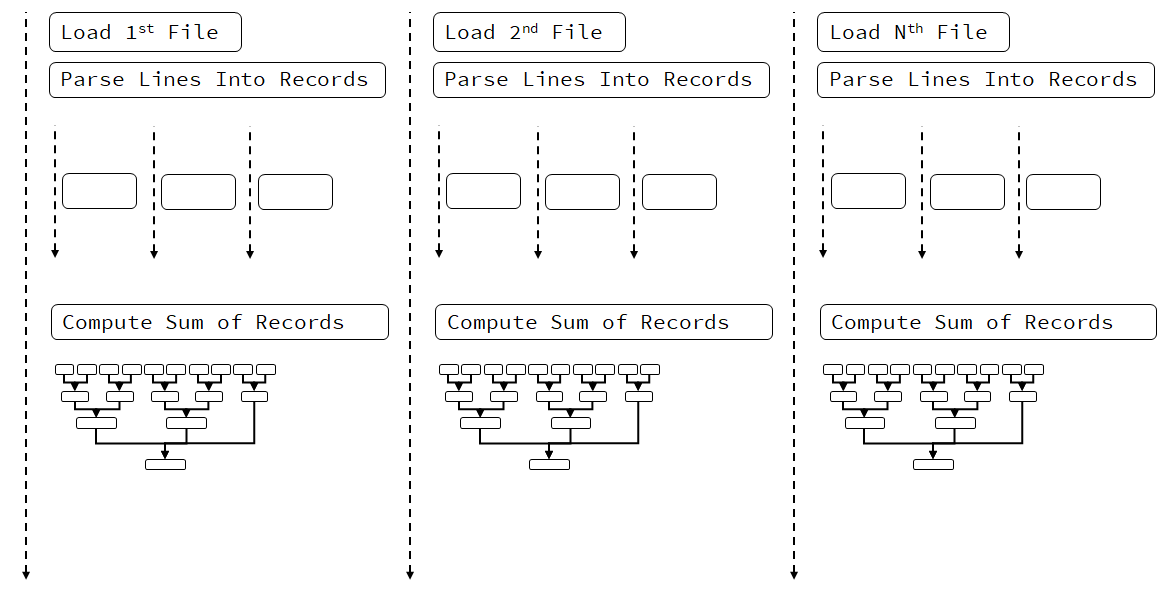
In the above diagram, the situation is a bit complicated. If we assume that OS cannot handle multiple file access, then threads will wait on files. But once the files are available, the processing might go in parallel.
If you want to play around with this technique, you can replace std::execution::seq in CalcResults() with std::execution::par. That will allow the compiler to run LoadRecords() and CalcTotalOrder() in parallel.
Is your system capable of accessing files from separate threads?
In general, the answer might be tricky, as it depends on many elements: hardware, system, and cost of computations, etc. For example, on a machine with a fast SSD drive, the system can handle several files reads, while on a HDD drive, the performance might be slower. Modern drives also use Native Command Queues, so even if you access from multiple threads, the command to the drive will be serial and also rearranged into a more optimal way. We leave the experiments to the readers as this topic goes beyond the scope of this book.
Back to you
- Have you tried parallel algorithms from C++17?
- How do you utilize many cores for data processing in your applcations?
Let us know in comments below the article.
Special Promo
It’s three years since I released “C++17 in Detail”! See the full info here: C++17 In Detail Book! and Print Version!.
To celebrate the anniversary, you can buy the book much cheaper!
Here are the options:
- Join the C++Stories Patreon community, pay for one year (min 5$ tier), and get the ebook for free! (in August)
Another option, direct coupon codes, -40% on Leanpub:
leanpub/cpp17indetail/40august3years-40% off, valid till Monday 16th August(invalid)- leanpub/cpp17indetail/30august3years - 30% off, valid till end of August.
Also with a pack with C++ Lambda Story:
- https://leanpub.com/b/cpp17andlambda/c/august3years - 17,99$ instead of 23.99$, valid till end of August
You can also buy Team edition - 5 copies, only for 49,95$ (50% discount!)
The Print version at Amazon has also lower price in August:
I've prepared a valuable bonus for you!
Learn all major features of recent C++ Standards on my Reference Cards!
Check it out here:
