
Last Update:
Packing bools, Parallel and More

Table of Contents
Let’s continue with the topic of packing boolean arrays into bits. Last
time I’ve shown a
basic - single threaded version of this ‘super’ advanced algorithm. By
using more independent variables, we could speed things up and go even
faster than no packing version! We’ve also used std::vector and
std::bitset. Today I’d like to look at making the task parallel.
Read the first part here: Packing Bools, Performance tests
Recall
Just to recall, there’s an array of values and a threshold value. We want to test input values against that Threshold and store boolean condition results into bits.
Brief pseudo code
for i = 0...N-1
byte = pack (input[i] > threshold,
input[i+1] > threshold,
...,
input[i+7] > threshold)
output[i/8] = byte
i+=8
// handle case where N not divisible by 8
In other words, we want to pack boolean results:
true, false, true, false, true, false, true, true
into full byte
11010101
where the first value corresponds to the first bit of the byte.
Simd, SSE2
The improved version of the solution uses eight separate values to store the result of the comparison and then it’s packed into one byte. But with SIMD we could do even more. There’s a way to pack 16 values at once using only SSE2 instructions. Can this be faster?
The core part of this approach is to use _mm_movemask_epi8. As we can
read
here:
int _mm_movemask_epi8 (__m128i a)
Create mask from the most significant bit of each 8-bit element in a,
and store the result in dst.
Since the comparison instructions set value 0xFF or 0, the above code is perfect to do the packing.
So the code can look like this:
auto in16Values = _mm_set_epi8(/*load 16 values*/);
auto cmpRes = _mm_cmpgt_epi8(in16Values, sseThresholds);
// cmpRes will stores 0xFF or 0 per each comparison result
auto packed = _mm_movemask_epi8(cmpRes);
*((uint16_t *)pOutputByte) = static_cast<uint16_t>(packed);
packed will be 16 bit mask composed from most significant bit of each
8-bit element in cmpRes. So this is exactly what we need.
The problem
Unfortunately, there’s a little problem. _mm_cmpgt_epi8 compares only
signed byte values, so we need to do more work to support unsigned
version.
There wouldn’t be any problem if we compared with the equality operator,
but for greater than it’s not an option.
You can read more about missing SSE instruction in this article: A few missing SSE intrinsics BTW: Thanks @malcompl for letting me know on Twitter.
Implementation
Maybe it will be unfair, but to solve the signed/unsigned problem I just
make a conversion code that subtracts 128 from the input values (and the
threshold). So that conversion is not counted in the measurement.
In the end, you’ll see the reason for doing this.
Auto vectorization
What about auto-vectorization? Maybe I am a terrible programmer, but it seems that most of my loops are hard to make vectorized. You can try and enable auto-vectorization in Visual Studio. But every time I do this I get almost zero success and no vectorized loops. See MSDN Auto-Parallelization and Auto-Vectorization. Maybe it’s better in GCC/Clang?
Threading with OpenMP
So far the code was single-threaded. We should be leveraging all available cores on our machines. Even in typical user devices, there are two or more cores (sometimes plus hyper-threading).
I don’t want to create a sophisticated task-queue worker system, so I got one idea: what about OpenMP? Our problem is quite simple, and what’s most important: we can perform packing in a highly parallel manner, as there are almost no conflicts between packed bytes.
Visual Studio offers a simple switch that enables OpenMP 2.0. As far as I can see GCC offers almost the newest version (4.5), and Clang allows to use OpenMP 3.1.
BTW: why VS only offers OpenMP 2.0… why we cannot go higher? Other people complained, see this thread: Add support for OpenMP 4.5 to VC++ – Visual Studio
If you want to have a quick intro about OpenMP, I suggest this resource: Guide into OpenMP: Easy multithreading programming for C++.
Basically, OpenMP offers a fork-join model of computation:
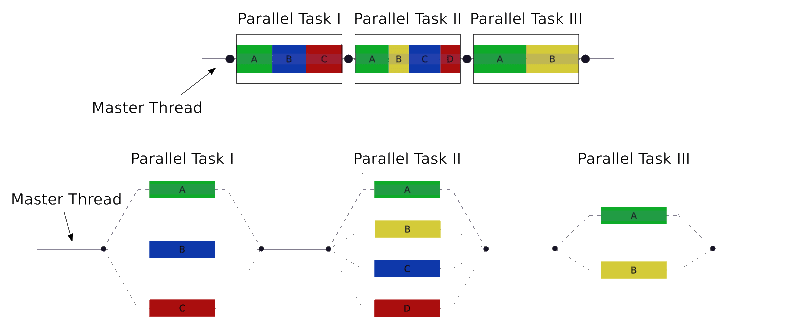
The picture comes from wikipedia.
Our problem is perfect for such scenario. Theoretically, we could spread one thread per byte! So each byte packing would get its own thread. OK, maybe it’s not the best option as the overhead of thread switching would be much heavier than the computation itself, but I hope you get what I meant here.
What’s great about OpenMP is that it will handle all the hard part of threads management. All we have to do is to mark the parallel region and rewrite code in a way it’s easy to be run on separate threads.
So our version with OpenMP uses the following code
#pragma omp parallel for private (Bits)
for (int i = 0; i < numFullBytes; ++i)
{
auto pInputData = inputValues.get() + i*8;
Bits[0] = pInput[0] > Threshold ? 0x01 : 0;
Bits[1] = pInput[1] > Threshold ? 0x02 : 0;
Bits[2] = pInput[2] > Threshold ? 0x04 : 0;
Bits[3] = pInput[3] > Threshold ? 0x08 : 0;
Bits[4] = pInput[4] > Threshold ? 0x10 : 0;
Bits[5] = pInput[5] > Threshold ? 0x20 : 0;
Bits[6] = pInput[6] > Threshold ? 0x40 : 0;
Bits[7] = pInput[7] > Threshold ? 0x80 : 0;
outputValues.get()[i] = Bits[0] | Bits[1] | Bits[2] | Bits[3] |
Bits[4] | Bits[5] | Bits[6] | Bits[7];
}
// and then the part for handling the last not full byte...
All I had to do was to reorganize code a bit - starting from my
not-depended
version.
Now each loop iteration works on one byte and 8 input values. We have a
private section - Bits, that will be separate for each thread.
OpenMP will try to spread the work across available worker threads.
Usually, it will be the number of cores. For example my machine has 4
cores with HT, so OpenMP reports 8 in my case (using
omp_get_max_threads()).
Not bad as just one line of code?
OK, so I have probably 8 worker threads available… will my initial code perform 8x faster? Probably not, as we need to count additional API/Library overhead. But 2x or even more might easily happen.
Packed struct
David Mott made a comment, where he suggested using packed structs.
Why should we manually perform bit operations? Maybe we can force the compiler and get some help? Why not :)
struct bool8
{
uint8_t val0 : 1;
uint8_t val1 : 1;
uint8_t val2 : 1;
uint8_t val3 : 1;
uint8_t val4 : 1;
uint8_t val5 : 1;
uint8_t val6 : 1;
uint8_t val7 : 1;
};
the processing code is much cleaner now:
for (int64_t j = 0; j < lenDivBy8; j += 8)
{
out.val0 = pInputData[0] > ThresholdValue;
out.val1 = pInputData[1] > ThresholdValue;
out.val2 = pInputData[2] > ThresholdValue;
out.val3 = pInputData[3] > ThresholdValue;
out.val4 = pInputData[4] > ThresholdValue;
out.val5 = pInputData[5] > ThresholdValue;
out.val6 = pInputData[6] > ThresholdValue;
out.val7 = pInputData[7] > ThresholdValue;
*pOutputByte++ = out;
pInputData += 8;
}
The OR operation is completely hidden now (maybe even not needed as the compiler can do its magic).
The case for the last byte is not as clean, but also not that bad:
if (arrayLength & 7)
{
auto RestW = arrayLength & 7;
out = { 0, 0, 0, 0, 0, 0, 0, 0 };
if (RestW > 6) out.val6 = pInput[6] > Threshold;
if (RestW > 5) out.val5 = pInput[5] > Threshold;
if (RestW > 4) out.val4 = pInput[4] > Threshold;
if (RestW > 3) out.val3 = pInput[3] > Threshold;
if (RestW > 2) out.val2 = pInput[2] > Threshold;
if (RestW > 1) out.val1 = pInput[1] > Threshold;
if (RestW > 0) out.val0 = pInput[0] > Threshold;
*pOutputByte++ = out;
}
We could also use union to provide array access for bits.
Results
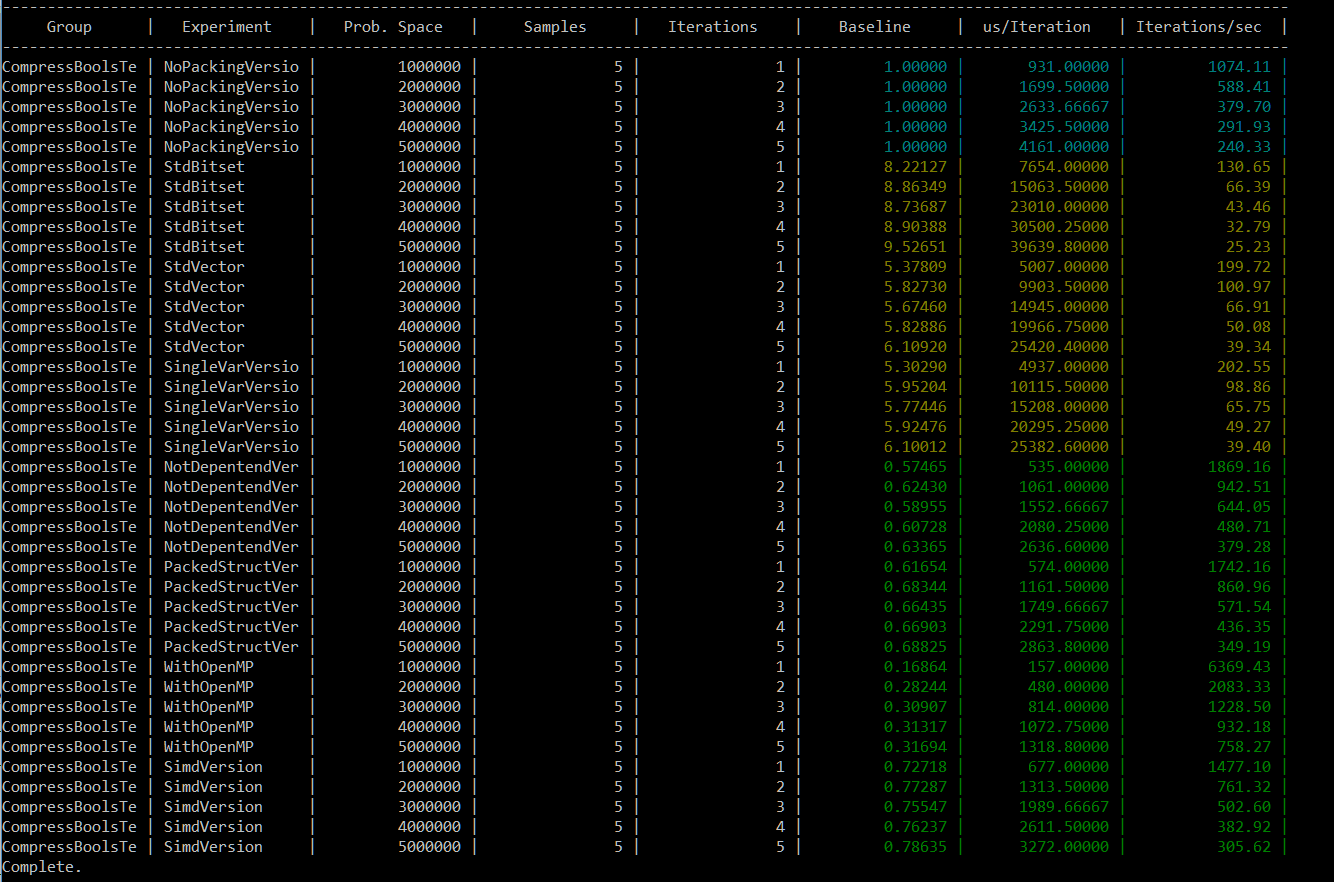
Ok, here’s the final run, with all versions:
And the chart for all:
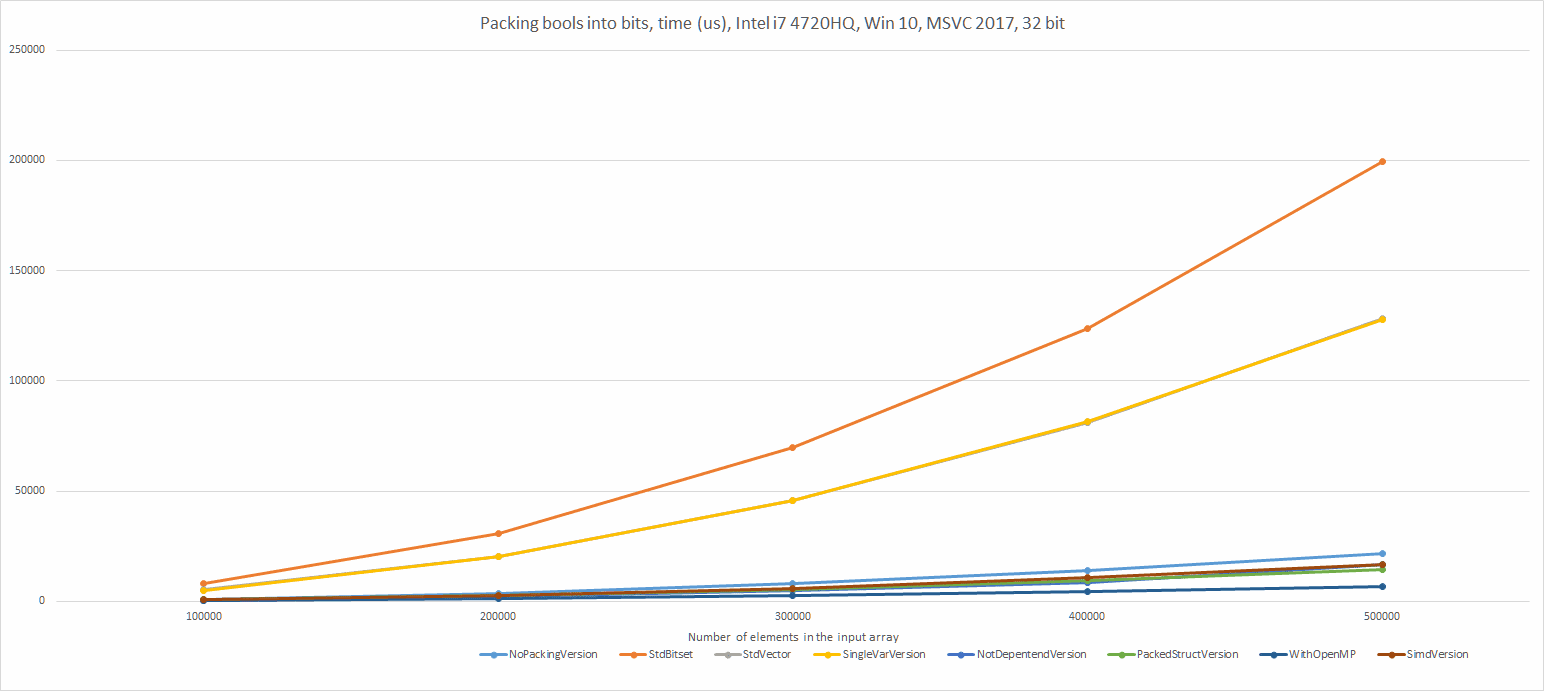
Chart for versions performing better than no packing
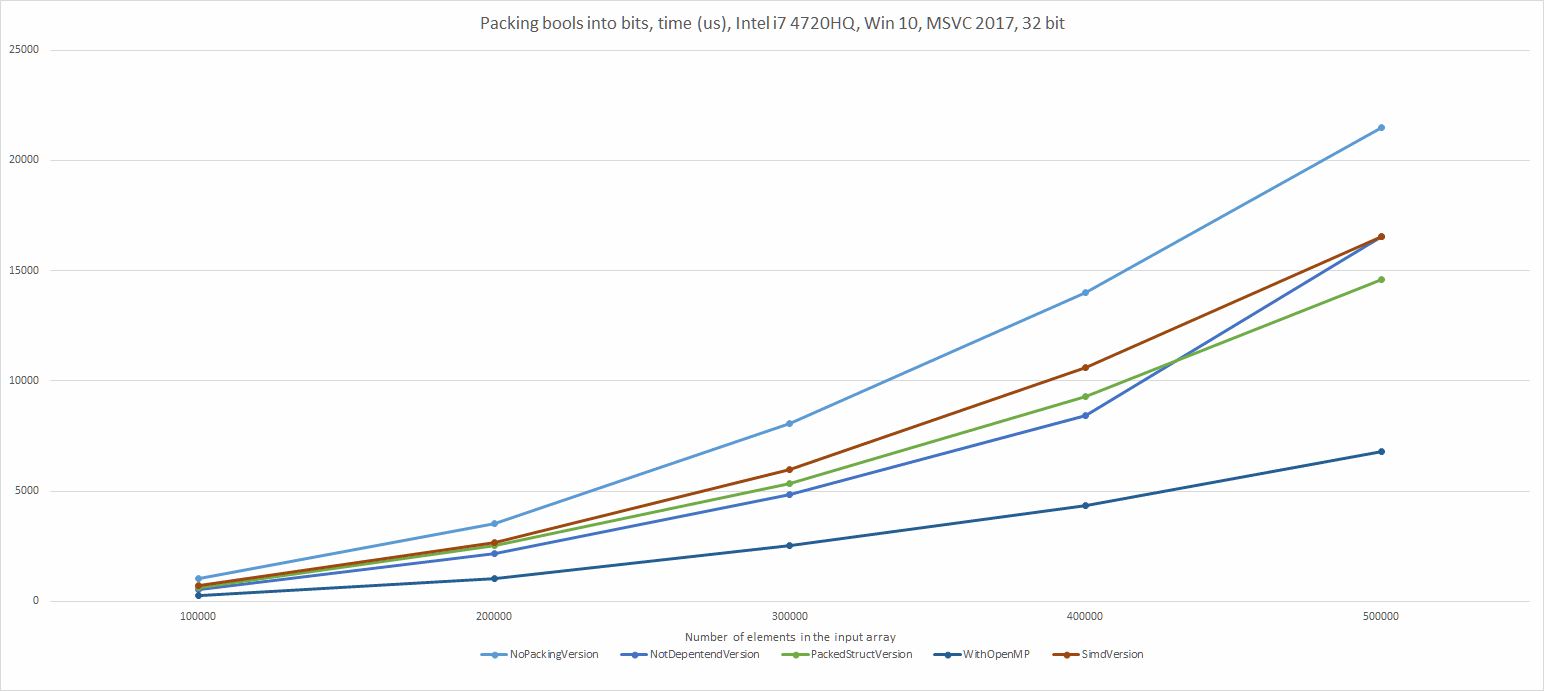
- OpenMP is a great way to make things faster, we get around 2.5…3x better performance (although I have 8 available system threads…)
- Using packed structs is a really good option: the bit playing code is hidden and the compiler is responsible to pack things. And it performs almost the same as manual version. Even faster for larger sets of data.
- My simd version wasn’t perfect, but I was still hoping for more gains. It operates on 16 input values at once (as opposed to 8 values in other versions). But the perf was slower. I am not an expert of simd stuff, so maybe there’s a way to improve?
Other solutions
- Recently Daniel Lemire has posted a list: Compressed bitset libraries in C and C++.
- OpenCL - we could go fully parallel and use a GPU approach. The problem is quite simple so I didn’t consider going into OpenCL implementation, but in the production code, if the algorithm was essential to the whole system… then why not.
- I need to see that talk mentioned in the comments: CppCon 2016: Chandler Carruth “High Performance Code 201: Hybrid Data Structures” - YouTube. As it covers some pretty crazy structures that also might help with bit packing… Or maybe you know how to apply such ideas onto my code?
Summary
Ufff… all done :)
What could we learn from the benchmarks?
- We can save some space by going into bit mode and at the same time the performance of packing might be faster than ‘no packing’ version.
- The Standard Library containers like vector of bools or bitset doesn’t perform well, it’s better to create manual versions, adjusted to a particular need.
- Using compiler to to the hard work: in our case it’s bit setting is quite a good alternative.
- If the task is highly parallel make sure you use all options to make things faster: reduce dependency of variables (also temp vars), use simd if possible, or threading libraries.
- As always measure measure measure as your case might be different.
I hope you enjoyed those tests. The problem was simple, but there are many ways we can explore the topic. And that’s only the tip of an iceberg when it comes to packing/compressing bitmaps.
Code on github: fenbf/celeroTest/celeroCompressBools.cpp
I've prepared a valuable bonus for you!
Learn all major features of recent C++ Standards on my Reference Cards!
Check it out here:
