
Last Update:
Implementing Parallel copy_if in C++

Table of Contents
In a blog post about a dozen ways to filter elements, I mentioned only serial versions of the code. But how about leveraging concurrency? Maybe we can throw some more threads and async tasks and complete the copy faster?
For example, I have 6 cores on my machine, so it would be nice to see, like 5x speedup over the sequential copy?
In C++17 we have parallel algorithms, so let’s try calling std::copy_if with std::execution::par.
If we go to the implementation of std::copy_if in the MSVC libraries, the parallel version we can see the following:
// VS 2019 16.8
// not parallelized at present, parallelism expected to be feasible in a future release
_REQUIRE_PARALLEL_ITERATOR(_FwdIt1);
_REQUIRE_PARALLEL_ITERATOR(_FwdIt2);
return _STD copy_if(_First, _Last, _Dest, _Pass_fn(_Pred));
That’s why it’s time to write my version :)
Disclaimer: those are only my experiments (mostly to learn something); if you want to use it in your projects, then please measure, measure and measure :)
The Basics
In a basic form C++17’s parallel algorithms are very simple to enable. Just pass a std::execution::par and you’re done! For example:
std::sort(std::execution::par, ...);
std::for_each(std::execution::par, ...);
The code invokes a bunch of threads (possibly leveraging some existing thread pool) and will kick smaller tasks in batches on multiple threads.
We should keep in mind that such invocation will always generate more work than the sequential version! And the cost of preparation, setting up the batches, kicking off thread pool, synchronisation - that adds a visible cost to the whole processing.
Ideally running things in parallel works best for lots of objects and also when small tasks are separate. A perfect example:
std::vector<double> numbers(SOME_BIG_COUNT);
std::for_each(std::execution::par, begin(numbers), end(numbers), [](double& d){
d = complexComputation(); // no dependency here
});
You can read my previous experiments with parallel algorithms:
- The Amazing Performance of C++17 Parallel Algorithms, is it Possible? - C++ Stories
- In the articles, I showed some “real” use cases with Fresnel and 3D Vectors and got speedup almost linear to the number of cores in my system.
- How to Boost Performance with Intel Parallel STL and C++17 Parallel Algorithms - C++ Stories
On the other case with code like:
std::sort(std::execution::par, begin(numbers), end(numbers));
You’ll see some speedup (when you have a large number of objects), but it won’t be linear to the numbers of cores.
This is because sort needs to shuffle things around in a container, and to do it safely, the algorithm has to perform some synchronisation so that other threads see the correct results.
Benchmark Code
For our tests (apart from simple debug output), I’ll be using the following code.
const size_t VEC_SIZE = argc > 1 ? atoi(argv[1]) : 10;
std::vector<std::pair<double, double>> testVec(VEC_SIZE);
std::ranges::generate(testVec.begin(), testVec.end(), []() mutable {
return std::pair{ GenRandom(-10.0, 10.0), GenRandom(-10.0, 10.0) };
});
auto test = [](auto& elem) {
auto sn = sin(elem.first) * cos(elem.second + 10.0);
return sn > 0.0;
};
In general, I’d like to have a bit more computation than elem%2 == 0. What’s more, each element is 16 bytes, so the object is also not super small.
The Naïve Approach
Similarly to std::sort our filter/copy_if function is not trivial to parallelise.
We can think about it in the following way:
- we have to run a predicate function on all elements - in most cases, it doesn’t depend on other elements and can be best to perform on many threads
- but then we have to put matching elements in the new container. This is a variable step and requires some synchronisation among threads.
For a start it’s good to implement a brute force approach and learn from that:
template <typename T, typename Pred>
auto FilterCopyIfParNaive(const std::vector<T>& vec, Pred p) {
std::vector<T> out;
std::mutex mut;
std::for_each(std::execution::par, begin(vec), end(vec),
[&out, &mut, p](auto&& elem) {
if (p(elem)) {
std::unique_lock lock(mut);
out.push_back(elem);
}
});
return out;
}
How does it work?
We run all steps in parallel, thanks to std::for_each and std::execution::par, but then we need to synchronise when we want to put the element in the output container.
As you can notice, all operations that modify the state of the container has to be protected.
Let’s see the performance:
// 4 cores / 8 threads
benchmark vec size: 100000
transform only seq : 2.5878 ms, ret: 100000
transform only par : 1.3734 ms, ret: 100000
FilterCopyIf : 5.3675 ms, ret: 50203
FilterCopyIfParNaive : 9.1836 ms, ret: 50203
And on my 6 core:
// 6 cores / 12 threads
benchmark vec size: 100000
transform only seq : 2.223 ms, ret: 100000
transform only par : 0.5507 ms, ret: 100000
FilterCopyIf : 3.851 ms, ret: 50203
FilterCopyIfParNaive : 10.1295 ms, ret: 50203
Upps… only ~2 or 3 times slower :) (I compare FilterCopyIf against FilterCopyIfNaive).
For comparison I also included transform only seq and transform only par which is just a simple transform run over the collection:
std::vector<uint8_t> buffer(testVec.size());
RunAndMeasure("transform only seq ", [&testVec, &buffer, &test]() {
std::transform(begin(testVec), end(testVec), begin(buffer), test);
return buffer.size();
});
RunAndMeasure("transform only par ", [&testVec, &buffer, &test]() {
std::transform(std::execution::par, begin(testVec), end(testVec), begin(buffer), test);
return buffer.size();
});
Please notice that buffer is created outside the transform lambda, so we don’t pay the price for its initialisation. See how it nicely scales with many cores.
Compose Algorithms
What else can we do?
I suggest the composition of several algorithms:
- Run
std::transformon all input elements to compute the predicate function, store the boolean result in a temporary container. - Then we need to compute the final position of the matching elements - this can be done by invoking
std::exlusive_scan - Later, we need to create the final results and merge the computed values.
See the illustration:
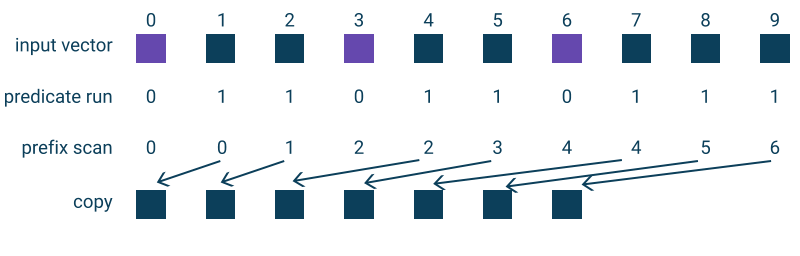
Here’s the code
template <typename T, typename Pred>
auto FilterCopyIfParCompose(const std::vector<T>& vec, Pred p) {
std::vector<uint8_t> buffer(vec.size());
std::vector<uint32_t> idx(vec.size());
std::transform(std::execution::par, begin(vec), end(vec), begin(buffer),
[&p](const T& elem) {
return p(elem);
});
std::exclusive_scan(std::execution::par,
begin(buffer), end(buffer), begin(idx), 0);
std::vector<T> out(idx.back()+1);
std::vector<size_t> indexes(vec.size());
std::iota(indexes.begin(), indexes.end(), 0);
std::for_each(std::execution::par, begin(indexes), end(indexes),
[&buffer, &vec, &idx, &out](size_t i) {
if (buffer[i])
out[idx[i]] = vec[i];
});
return out;
}
A basic code to generate the input vector, and a lambda that exludes 0, 3 and 6.
auto test = [](int elem) { return elem != 0 && elem != 3 && elem != 6; };
std::vector<int> testVec(VEC_SIZE);
std::iota(testVec.begin(), testVec.end(), 0);
And the output from that sample execution:
input : 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
buffer : 0, 1, 1, 0, 1, 1, 0, 1, 1, 1
idx : 0, 0, 1, 2, 2, 3, 4, 4, 5, 6
out : 1, 2, 4, 5, 7, 8, 9
Woh, woh… but this is so much code now! Can this even work?
So… yes, it works, and in some cases, it will be faster than the sequential version.
Here are the main caveats:
- The code adds substantially more work
- We use additional buffers and containers, so we need more memory.
Benchmark
Let’s have a test run. Can this be faster than the sequential version?
// 4 cores / 8 threads
benchmark vec size: 100000
transform only seq : 2.5878 ms, ret: 100000
transform only par : 1.3734 ms, ret: 100000
FilterCopyIf : 5.3675 ms, ret: 50203
FilterCopyIfParNaive : 9.1836 ms, ret: 50203
FilterCopyIfParCompose : 3.03 ms, ret: 50203
FilterCopyIfParComposeSeq : 2.3454 ms, ret: 50203
FilterCopyIfParTransformPush: 2.5735 ms, ret: 50203
And for 6 cores:
// 6 cores / 12 threads
benchmark vec size: 100000
transform only seq : 2.3379 ms, ret: 100000
transform only par : 0.5979 ms, ret: 100000
FilterCopyIf : 3.675 ms, ret: 50203
FilterCopyIfParNaive : 10.0073 ms, ret: 50203
FilterCopyIfParCompose : 1.2936 ms, ret: 50203
FilterCopyIfParComposeSeq : 1.0754 ms, ret: 50203
FilterCopyIfParTransformPush: 2.0103 ms, ret: 50203
FilterCopyIfParComposeSeq - is a version of FilterCopyIfParCompose with a simple loop to copy the results:
for (size_t i = 0; i < vec.size(); ++i)
if (buffer[i])
out[idx[i]] = vec[i];
And FilterCopyIfParTransformPush is another variation where we have only std::transform to be run in parallel, and then we use regular push_back.
template <typename T, typename Pred>
auto FilterCopyIfParTransformPush(const std::vector<T>& vec, Pred p) {
std::vector<uint8_t> buffer(vec.size());
std::transform(std::execution::par,
begin(vec), end(vec), begin(buffer),
[&p](const T& elem) {return p(elem); }
);
std::vector<T> out;
for (size_t i = 0; i < vec.size(); ++i)
if (buffer[i])
out.push_back(vec[i]);
return out;
}
But we can see that this version is 2x faster than the sequential! (for 4 cores) and 3x faster for 6 cores! So it’s a promising approach.
Blocks
Let’s try another approach.
This time we’ll split work into smaller chunks and then call copy_if separately:
template <typename T, typename Pred>
auto FilterCopyIfParChunks(const std::vector<T>& vec, Pred p) {
const auto chunks = std::thread::hardware_concurrency();
const auto chunkLen = vec.size() / chunks;
std::vector<size_t> indexes(chunks);
std::iota(indexes.begin(), indexes.end(), 0);
std::vector<std::vector<T>> copiedChunks(chunks);
std::for_each(std::execution::par, begin(indexes), end(indexes),
[&](size_t i) {
auto startIt = std::next(std::begin(vec), i * chunkLen);
auto endIt = std::next(startIt, chunkLen);
std::copy_if(startIt, endIt,
std::back_inserter(copiedChunks[i]), p);
});
std::vector<T> out;
for (const auto& part : copiedChunks)
out.insert(out.end(), part.begin(), part.end());
if (vec.size() % chunks != 0) {
auto startIt = std::next(std::begin(vec), chunks * chunkLen);
std::copy_if(startIt, end(vec), std::back_inserter(out), p);
}
return out;
}
Benchmarks
// 4 cores / 8 threads
benchmark vec size: 100000
transform only seq : 2.5878 ms, ret: 100000
transform only par : 1.3734 ms, ret: 100000
FilterCopyIf : 5.3675 ms, ret: 50203
FilterCopyIfParNaive : 9.1836 ms, ret: 50203
FilterCopyIfParCompose : 3.03 ms, ret: 50203
FilterCopyIfParComposeSeq : 2.3454 ms, ret: 50203
FilterCopyIfParTransformPush: 2.5735 ms, ret: 50203
FilterCopyIfParChunks : 2.9718 ms, ret: 50203
6 Cores:
// 6 cores / 12 threads
benchmark vec size: 100000
transform only seq : 2.3379 ms, ret: 100000
transform only par : 0.5979 ms, ret: 100000
FilterCopyIf : 3.675 ms, ret: 50203
FilterCopyIfParNaive : 10.0073 ms, ret: 50203
FilterCopyIfParCompose : 1.2936 ms, ret: 50203
FilterCopyIfParComposeSeq : 1.0754 ms, ret: 50203
FilterCopyIfParTransformPush: 2.0103 ms, ret: 50203
FilterCopyIfParChunks : 2.0974 ms, ret: 50203
This version is a bit simpler to implement, but it doesn’t bring that much speed. Still, it’s faster than the sequential version.
Approach with std::future
The previous version was quite promising, but we also have another way to split our tasks. Rather than relying on std::execution::par we can kick several std::future objects and then wait for them to finish.
I’ve found a similar idea in the book called “C++ High Performance” Disclaimer: I don’t have the book, but its Github Repo seems to be publicly available: Cpp-High-Performance/copy_if_split_into_two_parts.cpp
template <typename T, typename Pred>
auto FilterCopyIfParChunksFuture(const std::vector<T>& vec, Pred p) {
const auto chunks = std::thread::hardware_concurrency();
const auto chunkLen = vec.size() / chunks;
std::vector<std::future<std::vector<T>>> tasks(chunks);
for (size_t i = 0; i < chunks; ++i) {
auto startIt = std::next(std::begin(vec), i * chunkLen);
auto endIt = std::next(startIt, chunkLen);
tasks[i] = std::async(std::launch::async, [=, &p] {
std::vector<T> chunkOut;
std::copy_if(startIt, endIt, std::back_inserter(chunkOut), p);
return chunkOut;
});
}
std::vector<T> out;
for (auto& ft : tasks)
{
auto part = ft.get();
out.insert(out.end(), part.begin(), part.end());
}
// remaining part:
if (vec.size() % chunks != 0) {
auto startIt = std::next(std::begin(vec), chunks * chunkLen);
std::copy_if(startIt, end(vec), std::back_inserter(out), p);
}
return out;
}
Benchmarks
// 4 cores / 8 threads
benchmark vec size: 100000
transform only seq : 2.5878 ms, ret: 100000
transform only par : 1.3734 ms, ret: 100000
FilterCopyIf : 5.3675 ms, ret: 50203
FilterCopyIfParNaive : 9.1836 ms, ret: 50203
FilterCopyIfParCompose : 3.03 ms, ret: 50203
FilterCopyIfParComposeSeq : 2.3454 ms, ret: 50203
FilterCopyIfParTransformPush: 2.5735 ms, ret: 50203
FilterCopyIfParChunks : 2.9718 ms, ret: 50203
FilterCopyIfParChunksFuture : 2.5091 ms, ret: 50203
For 6 cores:
// 6 cores / 12 threads
benchmark vec size: 100000
transform only seq : 2.3379 ms, ret: 100000
transform only par : 0.5979 ms, ret: 100000
FilterCopyIf : 3.675 ms, ret: 50203
FilterCopyIfParNaive : 10.0073 ms, ret: 50203
FilterCopyIfParCompose : 1.2936 ms, ret: 50203
FilterCopyIfParComposeSeq : 1.0754 ms, ret: 50203
FilterCopyIfParTransformPush: 2.0103 ms, ret: 50203
FilterCopyIfParChunks : 2.0974 ms, ret: 50203
FilterCopyIfParChunksFuture : 1.9456 ms, ret: 50203
And a bit bigger vector and all techniques compared:
// 4 cores / 8 threads
benchmark vec size: 1000000
transform only seq : 24.7069 ms, ret: 1000000
transform only par : 5.9799 ms, ret: 1000000
FilterCopyIf : 45.2647 ms, ret: 499950
FilterCopyIfParNaive : 84.0741 ms, ret: 499950
FilterCopyIfParCompose : 17.1237 ms, ret: 499950
FilterCopyIfParComposeSeq : 16.7736 ms, ret: 499950
FilterCopyIfParTransformPush: 21.2285 ms, ret: 499950
FilterCopyIfParChunks : 22.1941 ms, ret: 499950
FilterCopyIfParChunksFuture : 22.4486 ms, ret: 499950
And 6 cores:
// 6 cores / 12 threads
benchmark vec size: 1000000
transform only seq : 24.7731 ms, ret: 1000000
transform only par : 2.8692 ms, ret: 1000000
FilterCopyIf : 35.6397 ms, ret: 499950 // base line
FilterCopyIfParNaive : 102.079 ms, ret: 499950
FilterCopyIfParCompose : 9.3953 ms, ret: 499950
FilterCopyIfParComposeSeq : 9.9909 ms, ret: 499950
FilterCopyIfParTransformPush: 13.9003 ms, ret: 499950
FilterCopyIfParChunks : 13.2688 ms, ret: 499950
FilterCopyIfParChunksFuture : 12.6284 ms, ret: 499950
Move To Other Thread
As you can see, we can make the code faster, but still, you need a lot of elements to process (I guess 50k…100k at least), and also, you have to pay the price for extra setup and even memory use.
So maybe we should stick to the sequential version?
As usual, it depends on your environment and requirements. But if you work with multiple threads, it might be wise to rely on the sequential copy_if and keep other threads busy. For example, you could kick off some small “copy” thread, do some other jobs concurrently while waiting for the copy to finish. There are various scenarios and approaches here.
Summary
It was fun!
This article aimed not to create the best parallel algorithm but experiment and learn something. I hope the ideas presented here give you some hints for your projects.
I relied entirely on a solid multithreading framework based on the Standard Library. Still, there are even more options when using Intel TBB or other highly sophisticated computing frameworks.
As you could see, I urged to create the output vector dynamically. This creates some extra overhead, so in your solution, you might maybe limit this. Why not allocate the same size as the input container? Perhaps that can work in your solution? Maybe we could shirk the vector later? Or possibly leverage some smart allocators?
Lots of questions and a lot of ways to experiment :)
I should also mention that in a recent Overload magazine ACCU there’s an article: A Case Against Blind Use of C++ Parallel Algorithms so you might also have a look at it. The article lists five problems you might want to consider before jumping and putting std::execustion::par everywhere.
See my code in a separate Github Repo:
https://github.com/fenbf/articles/blob/master/filterElements/filters.cpp
Thanks Victor Ciura (@ciura_victor) for feedback and hits to this article.
Back To You
- I showed 4 different techniques, but maybe you have some more? What would you suggest?
- I tested my code on MSVC, but in GCC, parallel algorithms are available through Intel TBB. Have you tried them there? It would be nice to see results from that compiler/library.
I've prepared a valuable bonus for you!
Learn all major features of recent C++ Standards on my Reference Cards!
Check it out here:
