
Last Update:
Top-7 Performance Traps for Every Developer

According to the recent popular paper “There is plenty of room at the top”1, SW tuning will be one of the key drivers for performance gains in the near future. The growth of a single-threaded performance of modern HW is slowing down, that’s why SW tuning will become more important than it has been for the last 40 years. This fact is especially important for developers that write code in native languages, like C++ since performance always was one of the keystones of the language.
To help you with improving that key area of any projects, we prepared a small guide. Let’s start!
This article is a guest post from Denis Bakhvalov:
Denis is a compiler engineer at Intel. He is the author of the book “Performance Analysis and Tuning on Modern CPUs”. Denis writes his blog easyperf.net and speaks about performance at developer conferences.
Performance optimization is sort of a “black art” because there are no predetermined steps you take, no formal algorithm to follow. It all comes with experience. To make this experience a little bit smoother, I decided to write a post that lists top-7 performance traps that mainstream developers often fall into. If this article will save a day for at least one engineer, I will consider my efforts well-spent. In the post, I focus on widely applicable language-agnostic performance mistakes that developers often make. Sure, that’s a lot of other language-specific issues one can fall into, like inefficient usage of C++ features, dynamic memory, system calls, etc. However, I believe it’s better to fail in utilizing effectively some C++ feature, rather than allow a major performance flaw to slip into your code. So, here we go. Performance trap #1…
1. Making predictions about performance
The number 1 performance trap that any developer can fall into is making predictions about how a certain piece of code will run. You see, modern platforms are very complicated, and their performance is non-deterministic, meaning that if you run the same application 2 times, you never get the exact same execution profile. I claim, there is no single person in the world who understands all the tiny details of how modern CPUs or GPUs work. So, even if the CPU architects cannot reliably predict the performance of a given snippet of code, how can a casual developer be better at doing this?
Don’t get me wrong, I’m not saying that knowledge about computer architecture is useless. On the contrary, it will help you guide your optimization work. In the end, making educated guesses is better than uneducated guesses, right? Well, not always, but it is a topic for another discussion. What I’m trying to say is: don’t let your hypothesis go untested. Always measure!
2. Making changes with no impact
Another performance trap I see developers tend to fall into, is they rely on their intuition when making changes in the code. They hope it will improve the performance of their code, but sometimes it results in no impact whatsoever. For example, a naive developer may try to replace i++ into ++i all over the codebase. However, any decent optimizing compiler automatically takes care of this. Eliminating unnecessary work is the compiler’s bread and butter. Guard yourself against doing random changes in your codebase.
The pro tip here is, any changes you make with regards to performance, should be guided by careful performance analysis, not your intuition. Become comfortable with using profilers to identify performance bottlenecks in your code. This is actually what my book is about, you can find the link at the end of the article.
3. Not knowing your data
If you’re doing any serious performance work, I strongly recommend you embrace the data-driven approach. The corner-stone of this approach is knowing the data on which the application operates. For example, what are the memory access patterns, which functions get called the most number of times, what conditions are usually true/false, what values are assigned to a particular variable, etc.
“Why is it important?”, you may ask. Well, engineers that don’t know their data end up optimizing their application for some theoretical use case, which doesn’t happen in practice. Consider two classical ways to lay out data in memory: Structure-Of-Array (SOA) and Array-Of-Structures (AOS):
// SOA
struct S {
int a[N];
int b[N];
int c[N];
};
<=>
// AOS
struct S {
int a;
int b;
int c;
};
S s[N];
The answer to the question of which layout is better depends on how the code is accessing the data. If the program iterates over the data structure S and only accesses field b, then SOA is better because all memory accesses will be sequential. However, if the program iterates over the data structure S and does excessive operations on all the fields of the object (i.e. a, b, c), then AOS is better because it’s likely that all the members of the object will reside in the same cache line. And that’s the choice that is better made when you know how your application is accessing memory. So my next recommendation is: know your data, know how people are using your code, and optimize your application for those use cases.
I think it also important to mention that there is a whole class of compiler optimizations, which is based on analyzing execution profile of the program. It’s called Profile Guided Optimizations (PGO). All the major compilers have it in their arsenal. You should consider using it as it might provide an additional 10-15% speedup with relatively low efforts. All you need to care about is to find a representative workload to “train” your compiler.
4. Not knowing your Tech Stack
The technology stack is very complicated these days. Applications that most developers write usually work on top of many different layers. Mainstream C++ application usually relies on third-party libraries, compiler, OS, HW. I believe it’s needless to say that at least a basic understanding of those components is important. You should know how your application interacts with components above the stack and how you can adjust their behavior to extract more performance from the system.
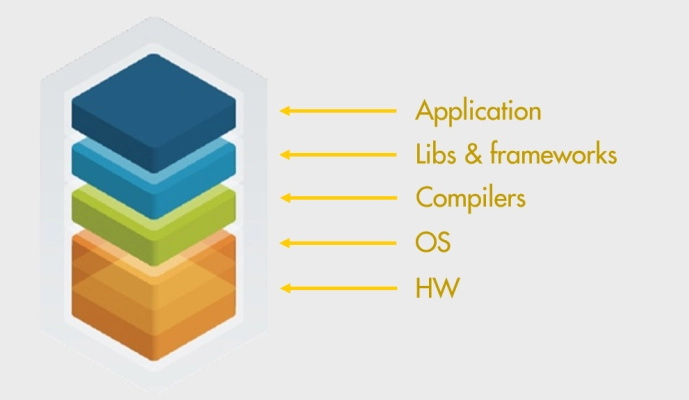
- If your application is using some high-performance library, say jemalloc, scalable memory allocation library, it’s good to know what tuning options are available for its users.
- When it comes to a C++ compiler, it’s not only about optimization level, e.g.
-O2/O3. You should know what other optimizations a compiler can make and how you can force it to do them. The most impactful ones are target-specific optimizations (the ‘-march’ option), Link Time Optimizations (the ‘-flto’ option), and Profile Guided Optimizations (PGO). - When your application spawns many threads or frequently does system calls, learn about the OS knobs that you can tune. That may involve frequency scaling governor, CPU affinity, process priority, filesystem caches, and others.
- Knowing how the HW works may be the most important one since how well we utilize it determines the ultimate performance of our code. Learning CPU microarchitecture and basic assembly instructions will bring long-term benefits.
5. Blindly relying on big-O notation
This one is really interesting. Developers are frequently overly obsessed with complexity analysis of the algorithms, which leads them to choose the popular algorithm, even though it may not be the most efficient for a given problem. Considering two sorting algorithms InsertionSort and QuickSort, the latter clearly wins in terms of Big O notation for the average case: InsertionSort is O(N^2) while QuickSort is only O(N log N). Yet for relatively small sizes of N2, InsertionSort outperforms QuickSort. Complexity analysis cannot account for all the branch prediction and caching effects of various algorithms, so they just encapsulate them in an implicit constant C, which sometimes can make a drastic impact on performance. The best-known algorithm for a certain problem is not necessarily the most performant in practice for every possible input. Do not discard HW effects when choosing your algorithms and data structures and test them on the target workload.
Another great example is a binary search. It is a great and simple algorithm, unfortunately, it is absolutely horrible from the CPU perspective. It experiences a high number of both cache misses and branch mispredictions at the same time. The standard implementation of a binary search jumps each time to a new location that is far away from the previous one, which is not CPU cache-friendly. Then, binary search tests every element of an array to determine whether we want to go left or right. From a CPU perspective, there is a 50% chance we go in each direction, which is a worst-case for a branch predictor. Don’t worry, I’m not saying we shouldn’t use binary search. My point is that sometimes you need to go an additional mile to write efficient code. There are ways to fix such problems. For binary search, you could store elements of an array using the Eytzinger layout3 and rewrite it in a branchless fashion4.
6. Overoptimizing your code
You read the title of the section and probably are surprised. Is it possible to overoptimize a program? It turns out that it’s possible. Performance engineering is important and rewarding work, but it may be very time-consuming. In fact, performance optimization is a never-ending game. There will always be something to optimize. Inevitably, a developer will reach the point of diminishing returns at which further improvement will come at a very high engineering cost and likely will not be worth the efforts. From that perspective, knowing when to stop optimizing is a critical aspect of performance work.
In the process of achieving the best performance numbers, developers sometimes go with all sorts of dirty hacks and tricks. Just some examples:
- spaghetti code & large functions
- overusing globals
- overusing template metaprogramming
- rewriting the code with compiler intrinsics
gotostatements (oh no!)
I think you get my point. You probably can outsmart a compiler and force to generate 1% better-performing code, however, in doing so there is a danger of leaving the unreadable mess behind. Keep the code reasonably simple and do not introduce unreasonable complicated changes if the performance benefits are negligible.
7. Creating a bad benchmark
Suppose you’re following the advice from the beginning of this article, and always measure your code before committing it. To quickly test some hypotheses, it’s a good idea to write a self-contained microbenchmark. Unfortunately, it’s not always easy to create a good benchmark. Consider an example below:
// foo DOES NOT benchmark string creation
void foo() {
for (int i = 0; i < 1000; i++)
std::string s("hi");
}
We want to test the performance of the code compiled with all optimizations enabled (-O2/-O3), however, this also instructs a compiler to eliminate all the unnecessary code. In the example above, it will effectively get rid of all the code that we want to benchmark5. The worst thing that can happen when you start driving conclusions from the results obtained from a bad benchmark.
To avoid such traps, I suggest to always check the performance profile of a benchmark and look at the hot assembly instructions. Sometimes abnormal timings can be spotted instantly, so use common sense while analyzing and comparing benchmark runs. One of the ways to keep the compiler from optimizing away important code is to use DoNotOptimize-like helper functions6, which do the necessary inline assembly magic under the hood.
Final words

I wrote a book titled “Performance Analysis and Tuning on Modern CPUs”, with a goal to educate software developers to better understand their applications’ performance on modern hardware. It goes into low-level performance details including CPU microarchitecture, different methods to analyze performance, and what transformations can be done to improve performance. The PDF version is available for free, but you can also buy a paper version on Amazon.
-
Leiserson, et al, “There’s plenty of room at the top”. URL https://science.sciencemag.org/content/368/6495/eaam9744. ↩︎
-
Typically between 7 and 50 elements. ↩︎
-
Khuong and Morin, “Array layouts for comparison-based searching”. URL: https://arxiv.org/abs/1509.05053. ↩︎
-
Example of branchless binary search on stackoverflow. ↩︎
-
This problem doesn’t usually happen in big enough benchmarks with the input data that is not visible to a compiler. ↩︎
-
For JMH (Java Microbenchmark Harness), this is known as the
Blackhole.consume(). ↩︎
I've prepared a valuable bonus for you!
Learn all major features of recent C++ Standards on my Reference Cards!
Check it out here:
